TOWARD EFFICIENT LOW-PRECISION TRAINING: DATA FORMAT OPTIMIZATION AND HYSTERESIS QUANTIZATION
Seoul National University, Seoul, Korea
ICLR 2022
1 INTRODUCTION
研究背景与意义:
- As larger and more complex neural networks are adopted, the energy and time consumed for training have become a critical issue in hardware implementation.
- Using low-bit representations in training significantly reduces hardware overhead and memory footprint; hence, neural network training with limited precision has been extensively studied recently.
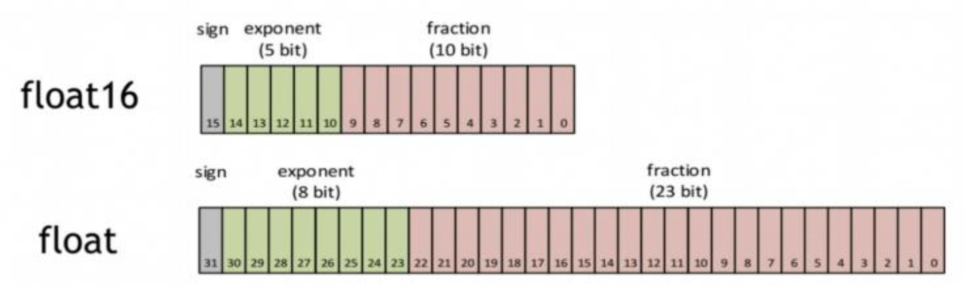
- Low-precision format: FP16 in GPU, bfloat in TPU, 8-bit formats

存在的问题:
- Optimal data format for low-precision training
目前8-bit的训练框架越来越多
8-bit情况下,数据格式也有很多种,应该使用哪一种?
- Performance degradation in from-scratch training
However, in low-precision training where a neural network is trained from scratch using low-precision values and computations, the trained model typically shows a noticeable accuracy drop.
提出的方法:
- We divide quantization in low-precision training into two types: network quantization and data flow quantization
network quantization: W
data flow quantization: A, E, G
- A method that can predict the training performance of various numeric formats for data flow quantization
- An optimal 8-bit format suitable for low-precision training of various models
- A new quantization scheme that utilizes the hysteresis effect to improve the performance of from-scratch training
2 DATA FLOW QUANTIZATION
2.1 NUMERIC FORMATS
本文考虑了多种数据格式的情况:8-bit 定点数,8-bit浮点数(1-xy),float-fix format
几种提出的数据格式,没有细看…
使用了几种约束条件,排除了一些情况之后:
498 formats in total (8, 7, 6-bit)
2.2 ACTIVATION AND ERROR QUANTIZATION
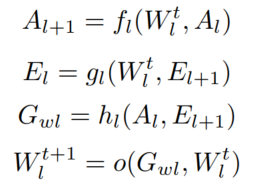
针对A,E,G直接选择了其他论文的量化方法。
Sean Fox, Seyedramin Rasoulinezhad, Julian Faraone, Philip Leong, et al. A block minifloat representation for training deep neural networks. In International Conference on Learning Representations, 2020.
2.3 INDICATORS OF TRAINING PERFORMANCE
cosine相似度

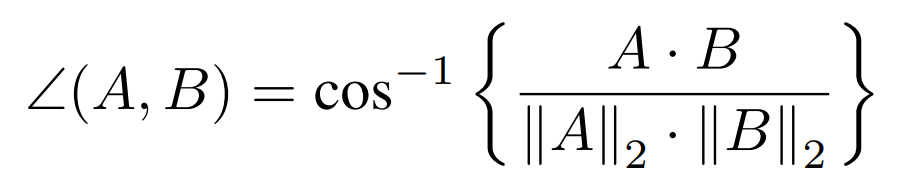
Effect of quantized error :考虑了error计算过程中的量化噪声,对G计算带来的偏差夹角
Effect of quantized activation:考虑了activation计算过程中的量化噪声,对G计算带来的偏差夹角
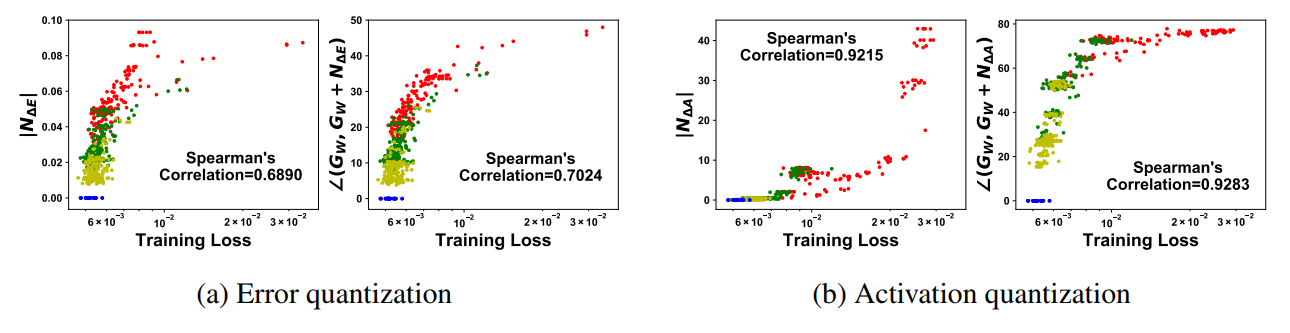
蓝色是full precision,黄绿红分别是8,7,6-bit
-
夹角是整个网络的。
-
We average angles from 100 mini-batches after quantizing a pre-trained model. 夹角的计算是根据 a pre-trained model计算出来的
- we could determine the optimal format for a specific neural network model, dataset, and task very efficiently . 对不同的数据集,任务,模型计算出各个数据格式带来的夹角。模型-数据集-任务 的组合会有预训练模型,根据预训练模型的结果去反推。
2.4 OPTIMAL FORMAT FOR DATA FLOW QUANTIZATION
we select six models with different architectures, layer types, and target tasks that are widely used in quantized training research for experiments .
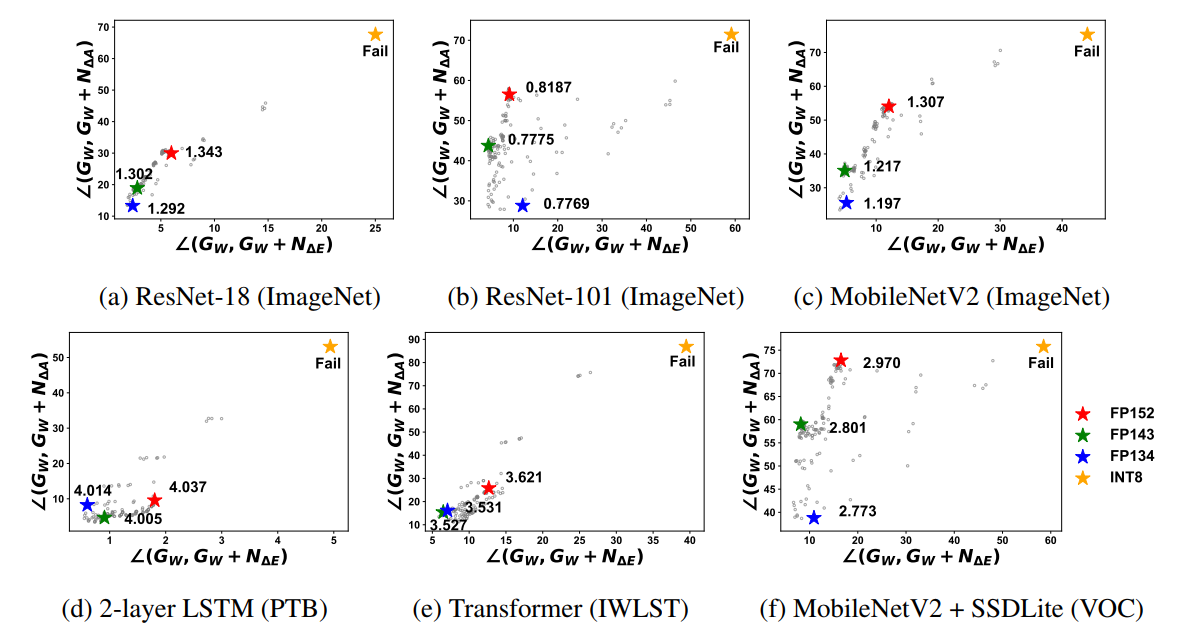
Fig. 3 suggests that FP134 and FP143 are the best candidates across all models. For hardware implementation, FP134 is the most optimal format due to its low implementation cost.
3 NETWORK QUANTIZATION
3.1 FLUCTUATION OF WEIGHT PARAMETERS
本文使用了参数 主备份,每次计算前将参数拿出来,量化后进行计算。
本文认为,普通的量化会造成在最优解周围的震荡。参数训练本来应该是平滑改变的。
3.2 HYSTERESIS QUANTIZATION
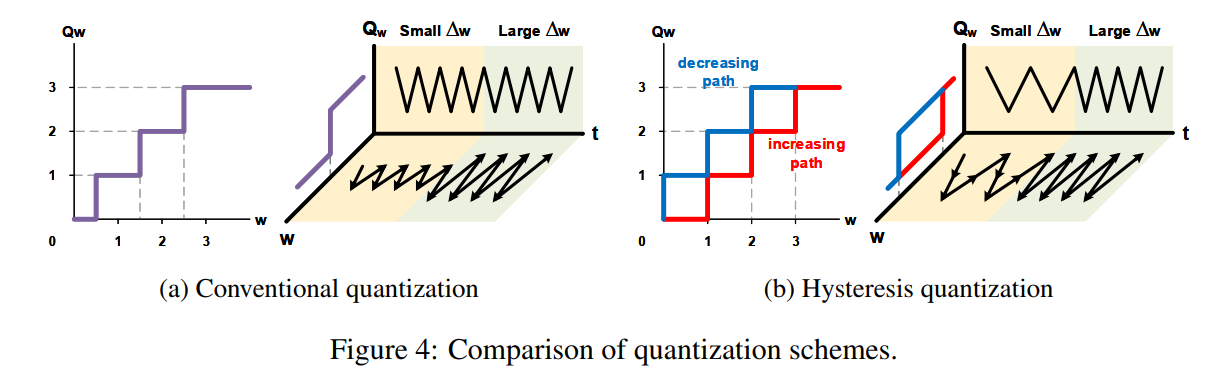
使用了延迟更新,让量化后的参数更加稳定。
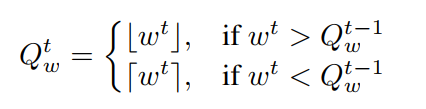
- stabilizing the training process and allowing the network to reach global optima more efficiently.
- if the weight change ∆W is small, then enough number of those changes should be accumulated to flip Qw.
- frequency is now proportional to the weight gradient.
- 如果是主备份+普通更新,可能会在最优值附近波动,从而影响收敛。
- 如果没有主备份,有些参数就无法完成微小的调整。
3.3 ULTRA-LOW-PRECISION FORMAT FOR NETWORK QUANTIZATION
we select 4-bit logarithmic representation as an ultra-low-precision format for weight parameters.
Mostafa Elhoushi, Zihao Chen, Farhan Shafiq, Ye Henry Tian, and Joey Yiwei Li. Deepshift: Towards multiplication-less neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2359–2368, 2021.
This format has the same dynamic range as INT8 which is widely used for weight quantization .
We apply channel-wise quantization to the convolutional layers to compensate for the insufficient expression range and layer-wise quantization to the other types of layers.
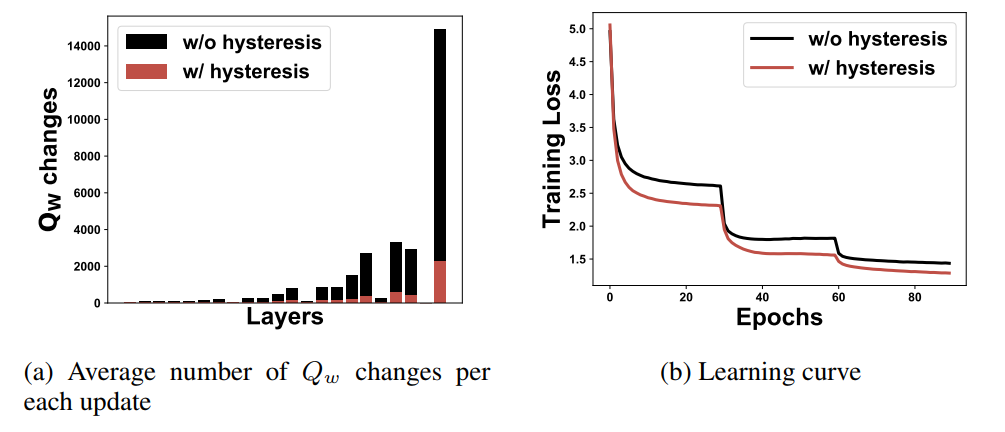
Fig. 5 clearly shows that using hysteresis significantly reduces weight change frequency and stabilizes the training process.
4 EXPERIMENTAL RESULTS
4.1 LOW-PRECISION TRAINING SCHEME
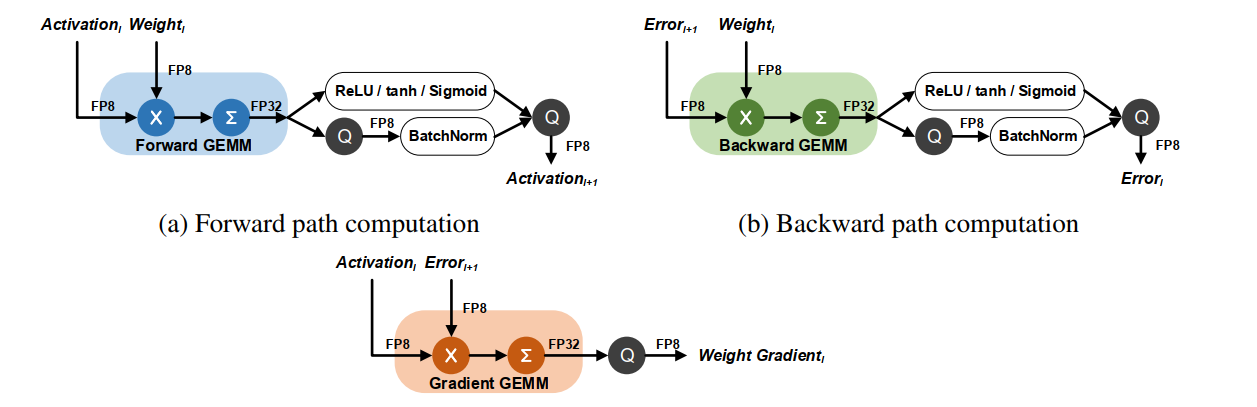
We need to quantize four variables: activation, error, weight, and weight gradient.
4.2 8-BIT LOW-PRECISION TRAINING
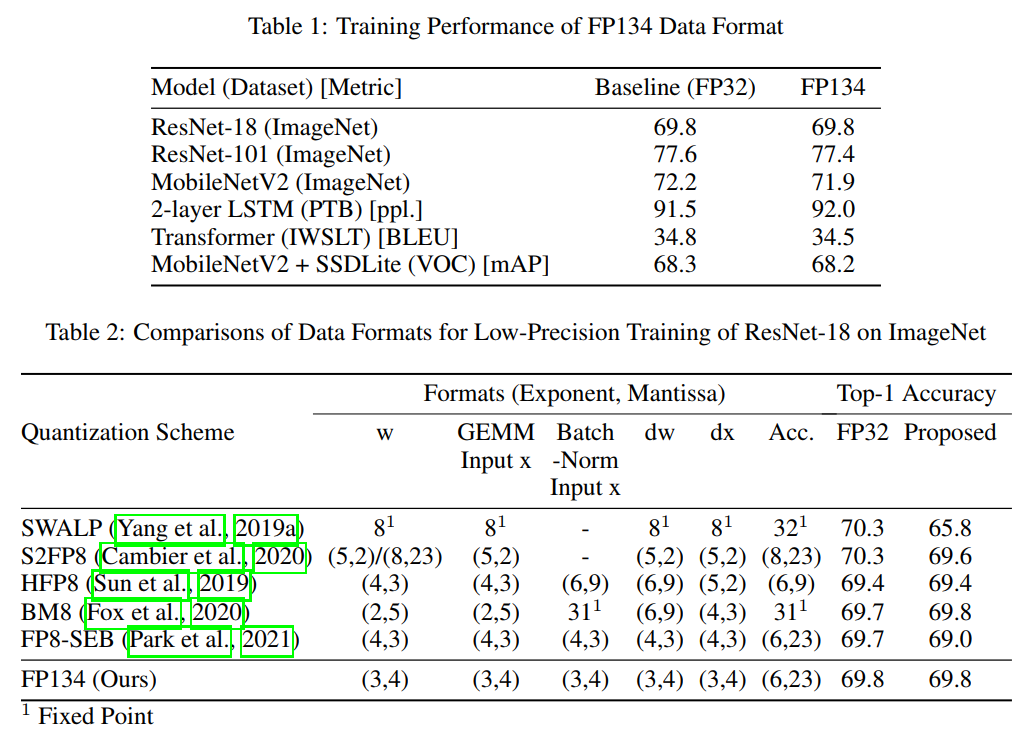
预训练后fine-tune?
4.3 ULTRA-LOW-PRECISION TRAINING WITH 4-BIT LOGARITHMIC WEIGHTS
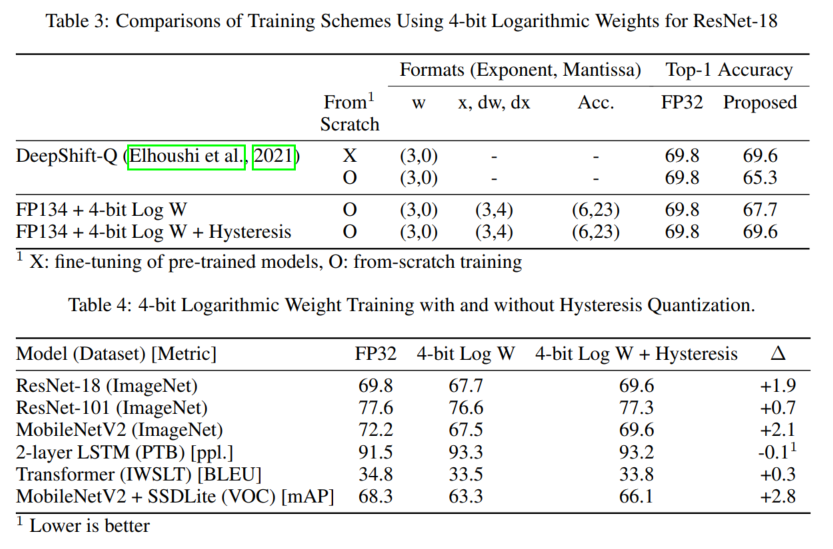
5 CONCLUSION
整个流程:用一个能够估计量化后训练效果好坏的预测器,对(模型,数据集,数据格式)进行预测,这个预测不是实际训练,而是通过对比预训练模型得到。然后找到一个合适的数据格式,这个数据格式应该是针对(模型,数据集,数据格式)的,但大多数都是FP134。而对于from-scratch的训练,效果会比较差,所以提出了延迟更新。
- 一个训练效果指示器
- 分析得出FP134比较好
- 延迟更新参数可以让量化波动小