Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates
作者: Insu Jang, Zhenning Yang, Zhen Zhang, Xin Jin, Mosharaf Chowdhury
机构: University of Michigan, AWS, Peking University
备注: SOSP23
链接: https://arxiv.org/abs/2309.08125
Background
大模型训练的主要方法是混合并行训练, 随着训练规模的增加, 训练遇到错误的可能性也会增加. 尤其是对于同步训练来说, 一个设备出错会导致所有参与设备的空闲等待, 将设备出错的代价放大至整个集群. meta, Transformer等公司的大模型训练报告指出错误发生的非常频繁, 并且在云上的训练会有更高的失败概率.
本质而言, 要确保在出现故障时仍能继续训练,就需要有冗余: 数据并行训练中的模型状态冗余则是 “免费 “的. 目前数据并行的的工作主要使用这个冗余性, 通过动态调整global batch size的方式, 以弹性调整GPU数量. 但是这些工作不适用于混合并行.
目前混合并行训练容错策略的主要方法有两类:
- Checkpointing: 使用重新启动的方式恢复训练. Varuna (微软, EuroSys22) 引入了job morphing,动态地重新配置训练作业,以便在从最近的检查点重新启动后,利用剩余资源实现最佳性能。
- Redundant computation (RC): 为了避免重新配置以及重新启动的开销, Bamboo (UCLA, Jiazhi Hao, NSDI23) 中每个流水线级都在两个节点内进行冗余前向计算。当一个节点发生故障时,备份节点来替代进行前反向计算。由于计算冗余和在每个节点中保存冗余状态的内存开销,RC 带来了固定的计算开销。
现有混合并行容错的工作从本质上讲,考虑的是训练中的额外计算开销与从故障中恢复的开销的tradeoff,并从两个极端中选择一个:如果故障不频繁,从故障中恢复的开销摊销下来会很低;反之在训练过程中产生一些开销可能比在恢复中花费大量时间更好。
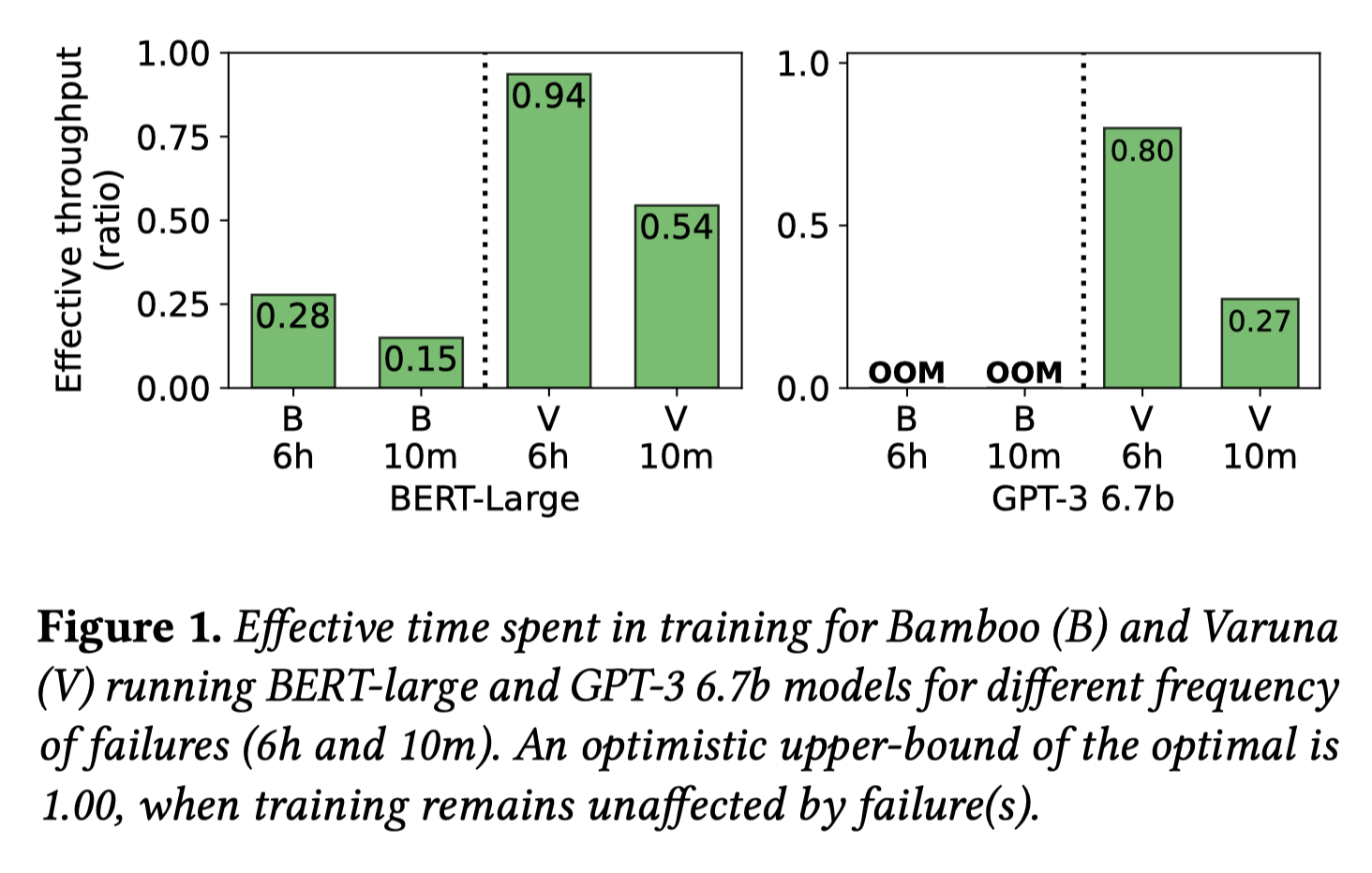
如上图所示, Varuna吞吐量更高, 但是重启开销随着出错频率增加而显著增长; Bamboo的冗余计算则带来了显著的性能开销,即使部分开销可以隐藏在pipeline bubble里.
(0.15/0.28 = 0.53, 0.54/0.94=0.57, 从图中并没有感受出错频率的区别??)
Overview
本文提出的Oobleck的目标是混合并行训练中遇到错误后进行快速恢复, 避免额外的开销.
本文工作围绕 pipeline template的概念进行. 每个 template 都是一个pipeline specification,定义了应为流水线分配多少个节点、创建多少个stage以及如何将stage中的模型映射到 GPU。Oobleck 实例化的所有流水线都来自预先设计的pipeline template。Oobleck 会从一组异构 pipeline template 中实例化多个流水线以充分利用任意数量的节点.
同时Oobleck 将 “规划”(pipeline template 生成)与 “执行”(流水线实例化)解耦, 可实现快速故障恢复; 节点丢失的流水线会被从另一个流水线模板实例化的新流水线取代。
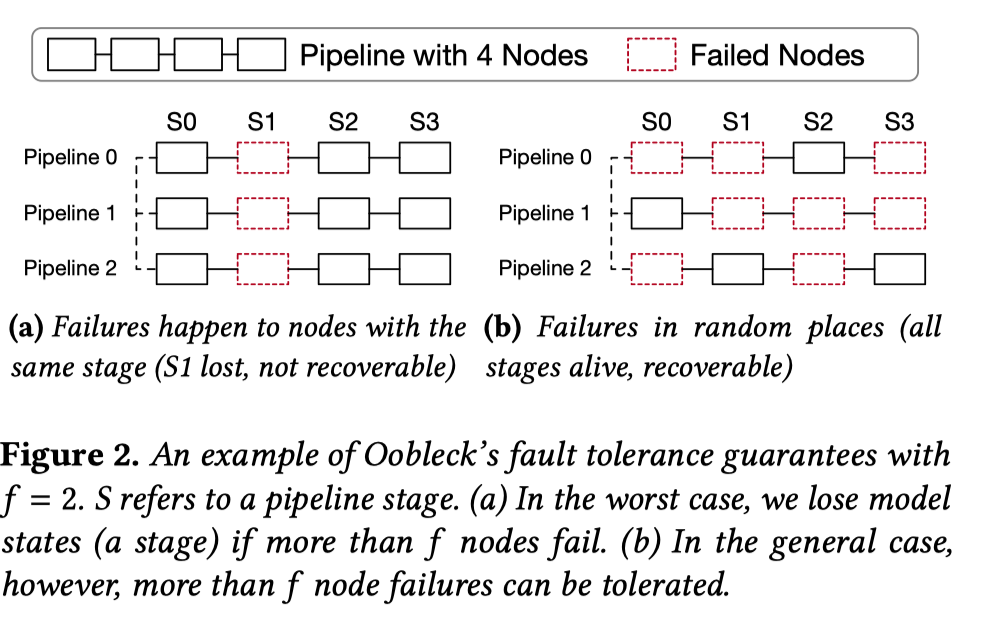
令训练中至多可以同时出错且不需要重启训练的节点数量为 \(f\) (fault tolerance threshold) 如上图(a)所示, 最差情况为\(f=2\), 但是通常而言如图(b)所示\(f\)可以为更大的值.
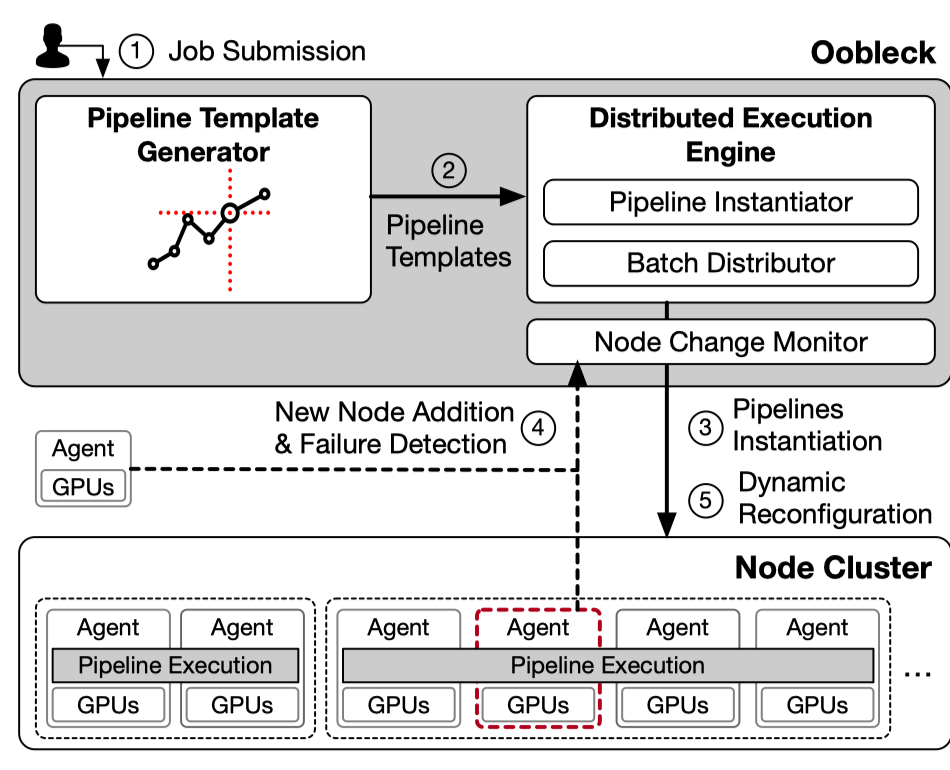
Oobleck的架构图如上图所示. 首先初始化过程中, pipeline template generator生成一系列的pipeline template给到分布式执行引擎.
在执行引擎中, 给定一个fault tolerance threshold \(f\), pipeline instantiator将初始化至少 \(f+1\) 条流水线将所有可用节点使用起来. batch distributer则给各条流水线计算microbatch数, 以平衡各个流水线的运行时间. pipeline instantiator和batch distributer将在每次(node change monitor检测到的)节点出错或者新节点加入的时候运行一次.
Planning Algorithm
为了实现利用所有可用的节点, 完成异构流水线执行(多个异构流水线进行数据并行). Oobleck 需要一种有效的算法来推导异构流水线的所有可能配置,以及一个算法将这些流水线模板组织至任意可用数量的节点。
Generating Pipeline Templates
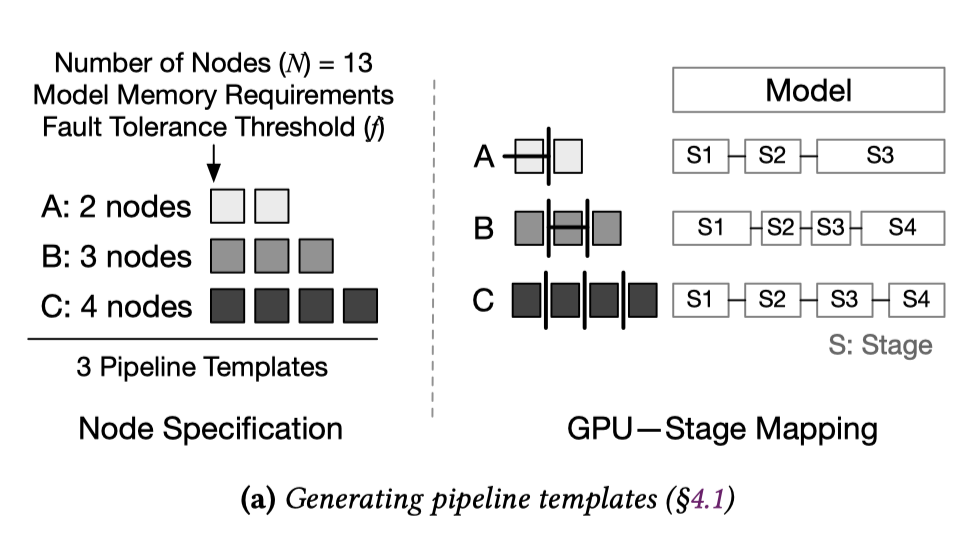
根据总节点数\(N\)以及用户给出的\(f\)值确定所有可能的流水线模板. 生成Pipeline Templates 包括两个问题: (1)各流水线可能的节点数; (2)各流水线中模型与设备的映射方式.
Node Specification
首先需要确定每个模板应该使用多少个节点,以便模板的某种组合始终可以利用任意数量的可用节点,即使节点数量会因为节点失败变少。
这个问题可以被定义成一个Frobenius problem.

设流水线模板数为\(p\), 各个模板使用的节点数量为连续整数\(n_0, \dots ,n_p, n_i+1=n_{i+1}\) , (上图中最大公约数为1的\(a_0,\dots ,a_n\)), Frobenius problem可以求出一个Frobenius数\(g\), 在\(g<N'\)时, 任意节点数 \(N>N'\)可以由模板的某种组合用满.
此时需要考虑如何确定 \(N', n_0, p\)取值. 为了满足用户给出的\(f\)值, 最少需要\(f+1\)条流水线, 因此需要满足 \(N'>(f+1)n_0\). 因为较浅的流水线在相同计算量的情况下效率更高, 所以选择最小的可能\(n_0\)值. 同时为了降低出错时重新组织流水线的开销, 选择最大的可能\(p\)值, 因为需要连续整数, 此时\(p\)值可以由\(n_0\)确定, 根据: \(n_{max} = N-fn_0, p = n_{max}-n_0+1\).
GPU–Stage Mapping
给定流水线设备数, 为了找到最佳运行方案, 需要确定流水级数, 确定如何将模型切分成流水级(切分的颗粒度是模型层), 以及确定流水级与设备的映射方式. 本文使用一个divide and conquer算法来找到有着最短迭代时间的GPU–Stage Mapping. 下图为一个将6层模型划分成4个流水级并分配到3个节点的示例.
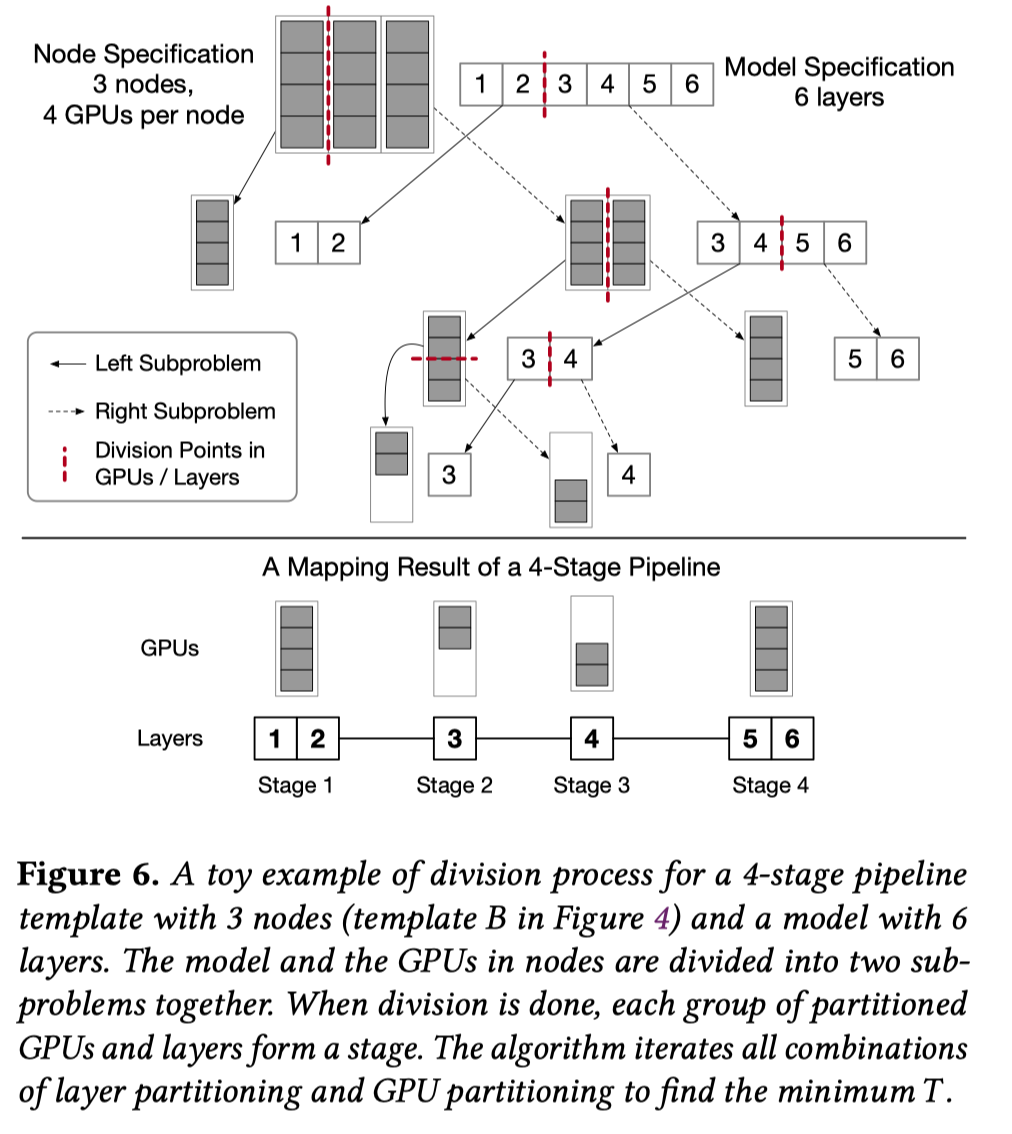
算法详情:
令\( T (S',u, v,d)\) 为划分为 \(S'\) 个流水线并在 \(d\) 个GPU 上运行层 \((l_u ,l_{u+1} ,\dots ,l_{v−1} )\) 的最短迭代时间。使用流水线模板中所有 GPU 的整个流水线的最小迭代时间为 \(T (S, 0,L,n \cdot M)\),其中模型为 L 层,流水线模板中有 n 个节点,每个节点都有 M 个 GPU。
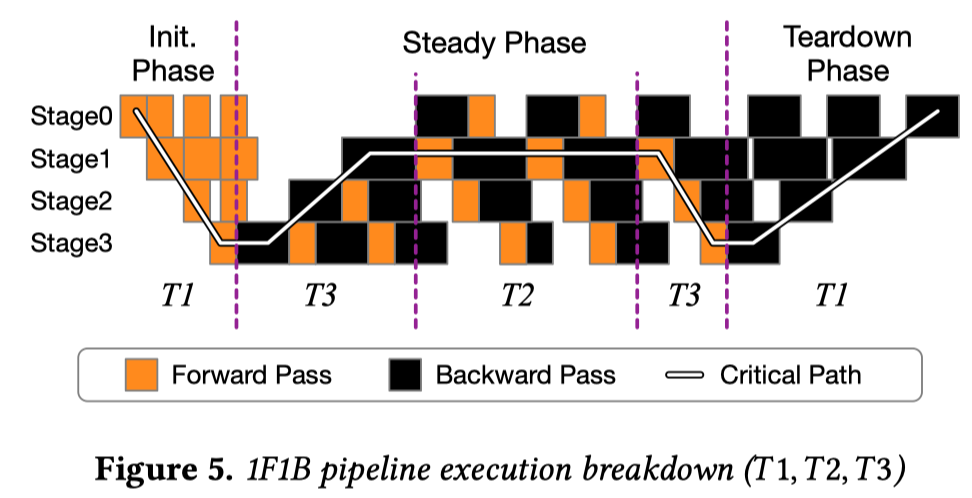
Divide阶段: 根据上图对流水线关键路径的划分, 将模型和节点同时划分至最细粒度或者获得需要的流水级数, 从而进行问题分割.
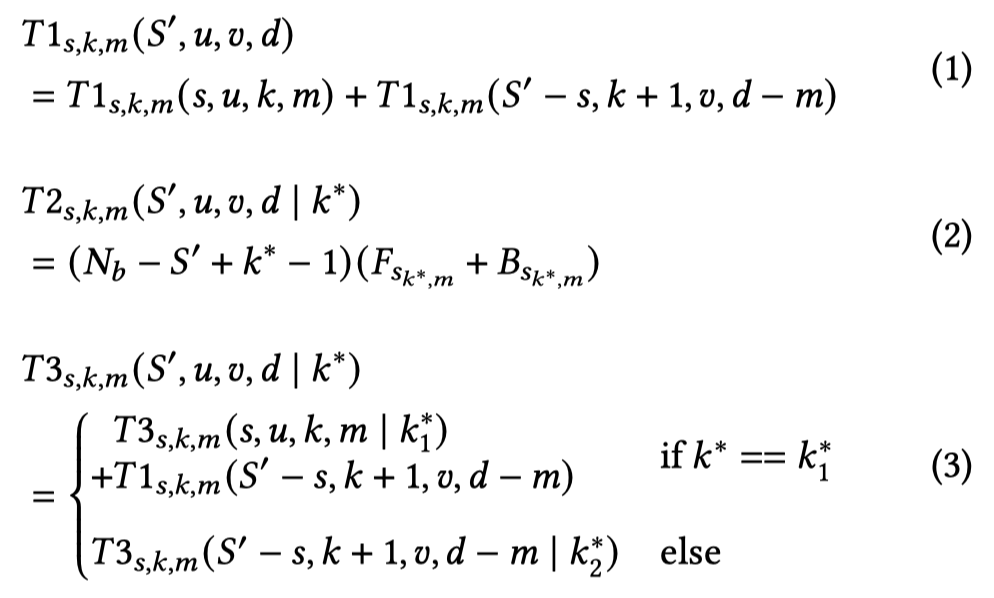
其中, \(k^*\)为最慢流水级的序号, microbatches数量\(N_b=4S'\)以保证较低的bubble率. 全局遍历流水级切分点s, 模型切分点k 和GPU分割点 m,找到一个最小化\( T1_{s,k,m}+T2_{s,k,m}+T3_{s,k,m}\)的 (s,k,m)。
Conquer阶段: 当一个问题只有一个流水级时,我们可以很容易地计算出在 d 个 GPU 上运行层 \((l_u ,l_{u+1} ,\dots ,l_{v−1} )\) 的流水级 s 的执行时间:
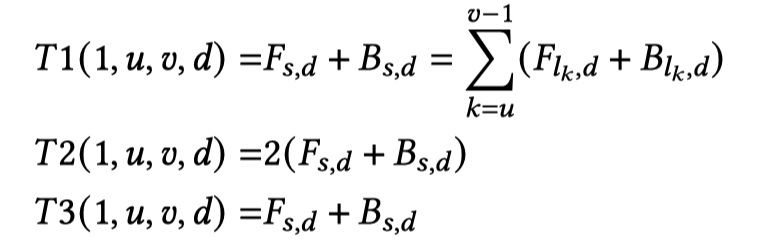
当多个GPU运行同一个流水级时, 将使用TP, 因此上式中的\(d\)应确保在同一节点中.
本divide and conquer算法可以确定\(S'\)个stage时的最小运行时间, 接下来遍历 \(S\in (n,n+1,\cdots, L)\) . (从分到的节点数遍历至模型层数). 算法时间复杂度为 \(O((L-n)L^3nM)\). 实际上, 在缓存所有分治算法中的中间结果时, 直接对用节点数最多的Pipeline Template运行算法也可获得其余Pipeline Template的算法中间结果, 此时其余Pipeline Template的算法复杂度为\(O(Ln)\).
Pipeline Instantiation
给定一组Pipeline Template,Oobleck 需要实例化这些Pipeline Template以利用所有可用节点。但是,这种异构Pipeline Template的组合策略可能不是唯一的。因此,需要(1)找到所有这些可行的组合策略以及(2)在所有可行组合中选择吞吐量最高的组合策略。

Enumerating All Instantiation Options
使用一个动态规划算法枚举当前可用节点的所有可行pipeline 集合,并选择一个可最大限度地提高训练吞吐量的集合。
算法细节:
令\(\mathbb{X}(p,N)\)为所有可行的pipeline集合列表\([X_0,X_1,\cdots]\), 各个\(X_i\)为一组要实例化的流水线个数 \((x_0,x_1,\cdots,x_{p-1})\), 包含\(p\)种异构流水级模板, 每个模板需要的节点数为\((n_o,n_1,\cdots,n_{p-1})\). 一个合规的\(X_i\)需要满足以下条件:
-
\(N=x_0 n_0+x_1 n_1+\cdots+x_{p-1} n_{p-1}\), 所有节点都被用了.
-
\(\sum_{j=0}^{p-1}x_j \ge f+1\) ,流水线个数至少为\(f+1\).
为了求解\(\mathbb{X}\), 上面的条件1可以视为一个经典的硬币组合问题, 可以使用动态规划解决, 动态规划递推表达式可以写作:
其中\(+\!\!\!+\) 为连接两个列表, \(\theta(\mathbb{X}, p')\) 表示 \(\mathbb{X}\) 中各\(X_i\) 中的 \( x_{p'}\) 增加1.
下图为动态规划算法示意图.

动态规划算法的复杂度为\(O(Np)\), 同时为了满足上述条件2, 会将结果中不满足的\(X_i\)去除.
Calculating Throughput with Batch Distribution
为了选择最佳性能的pipeline 集合, 需要计算各个pipeline 集合\(X_i\)的吞吐量. 计算吞吐量需要各个流水线的batchsize, 本文使用batch distributor来将用户设置的batchsize分配给各个pipeline.
给定global batch size \(B\)和microbatch size \(b\), batch distributor使用一个整数线性规划算法给每个流水线计算一个microbatch数量, 平衡流水线执行时间, 提高整体吞吐量.
算法细节:
令 \(N_{b,i} $是第\) i\( 个流水线 (\)0 \le i < x, x =\sum_{j=0}^{p-1} x_j\()的microbatch数,\)T_i\(是单个 microbatch的流水线迭代时间。第\) i \(个流水线的minibatch大小可以计算为 $N_{b,i} \times b\)。通过调整\(N_{b,i}\),问题可以视为最小化不同流水线执行时间之间的差异。可以表述为整数优化问题:
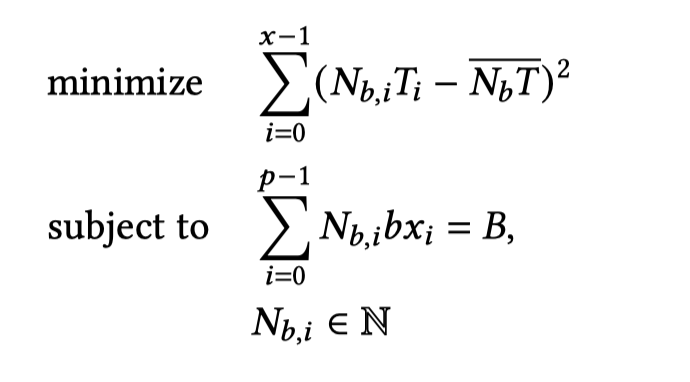
其中\(\overline{N_{b} T}\)为所有流水线的平均迭代时间, 使用MindtPy求解器可以求解出\(N_{b,i}\),即各流水线的minibatch大小.
Dynamic Reconfiguration
节点失效后,其所在流水线将变得不完整,模型状态缺失. 受故障影响的流水线会通过pipeline reinstantiation(流水线重构) 根据已有的pipeline templete 创建新流水线取代。流水线重构,节点会从未受影响的流水线重构副本中复制缺失的模型层。此外, Oobleck 还会根据流水线配置变化重新进行Batch Redistribution。因此, 在节点数少于\( (f+ 1)n_0\) 前, Oobleck 均能从故障中恢复.
Pipeline Reinstantiation
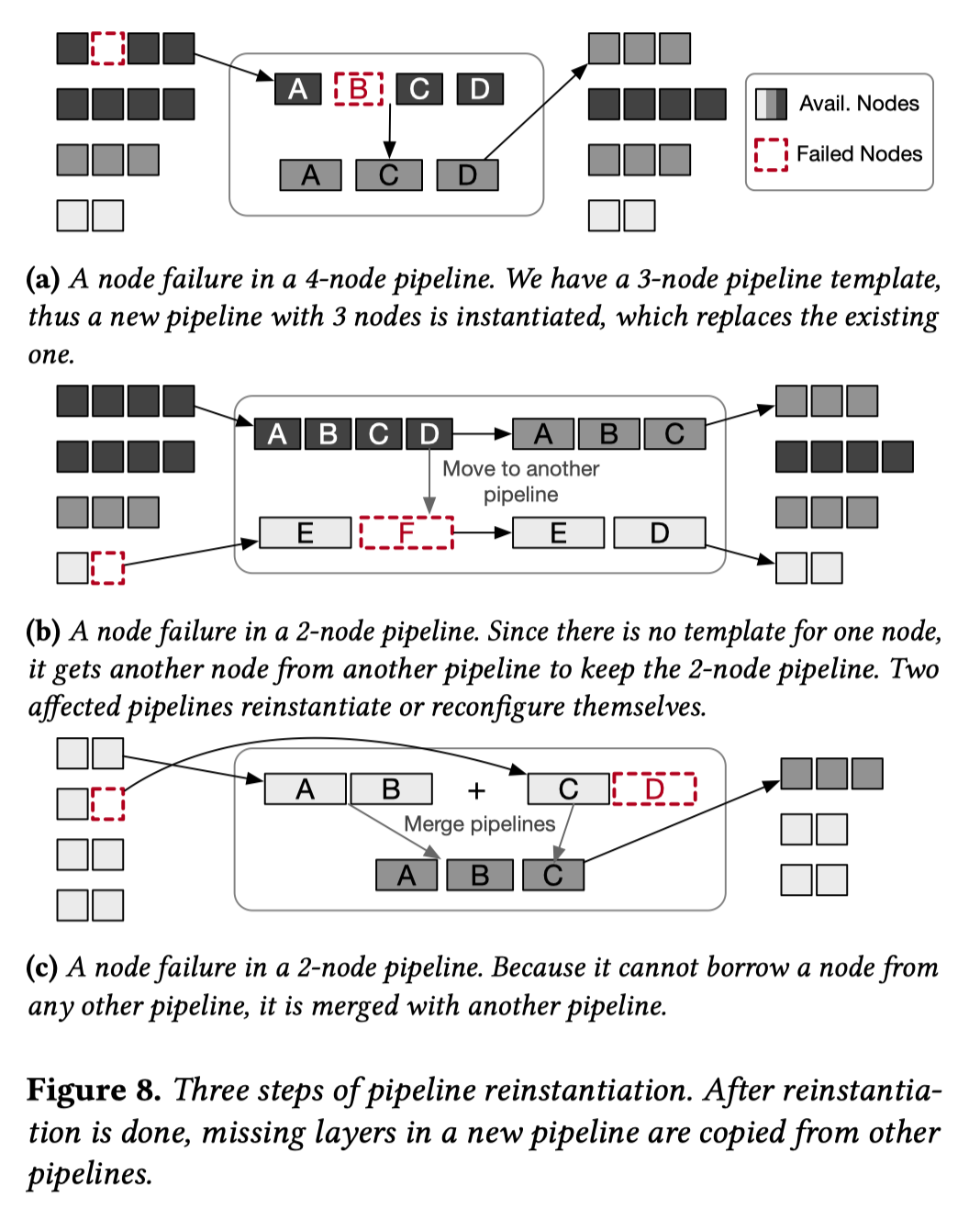
流水线重构将遇到以下三种情况:
- Simple reinstantiation(上图(a)): 当受故障影响的流水线剩下的节点数有对应的pipeline templete时, 直接根据该pipeline templete重构流水线.
- Borrowing nodes(上图(b)): 当受故障影响的流水线剩下的节点数不够新建流水线时, 会从其他流水线借用节点以满足最低节点数要求.
- Merging pipelines(上图(c)): 经过多次重新配置和节点借用后,所有流水线可能都无法让出节点。此时受故障影响的流水线就会因节点不足而无法重新启动。此时Oobleck 会合并流水线来保证所有流水线至少有 \(n_0\)个节点(pipeline templete中所需的最少节点数).
Implementation
PyTorch+Transformers, Merak tracer创建流水线, DeepSpeed运行流水线, 3D parallelism中FSDP替代TP.
- Model Synchronization Between Heterogeneous Pipelines
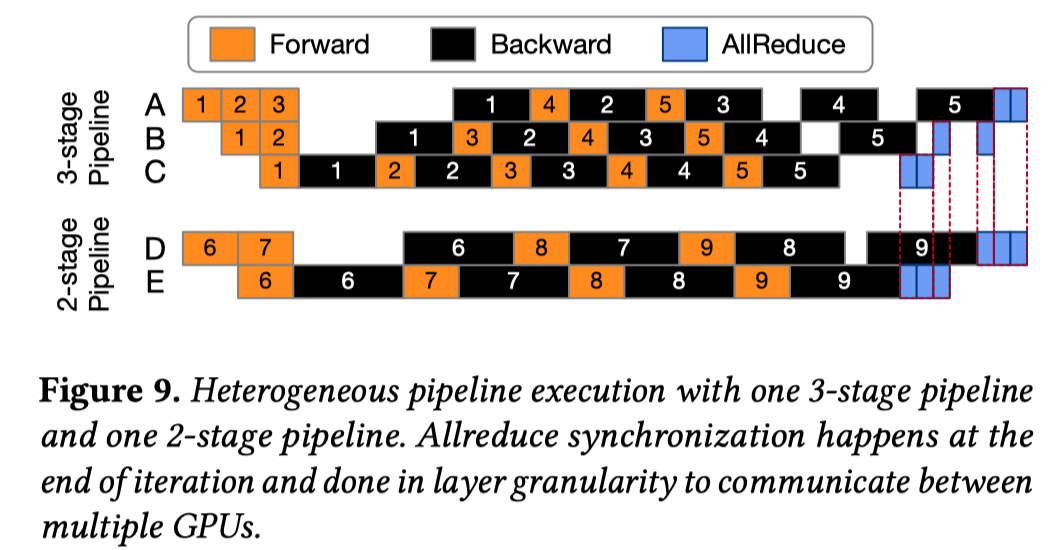
将各流水级分解成若干层并分别进行同步, 同时每个单独的层可能与不同的节点执行同步。较小数据量的数据同步可能会产生性能问题, 本文将通信与计算重叠, 以抵消增加的通信延迟.
- Detecting Node Failures
NCCL 无法检测到意外的通信通道断开, 为了立即检测到节点故障,本文在每个节点上启动了一个 CPU 进程,并与中心 CPU 进程建立 TCP 连接。当一个节点故障时,触发并广播一个socket disconnection event。
Evaluation
- 模型设置:
数据精度TF32, Bamboo不支持重计算, Varuna和Oobleck开重计算

- 集群设置:
30 NVIDIA A40 GPUs (40GB), GPU通过 200Gbps IB网互联. (单机单卡)
- bashline:
Varuna和Bamboo, 其中Varuna每10次迭代进行一次checkpointing
因为baseline不支持TP, 所以用单机单卡也能避免Oobleck使用TP.
- Throughput Under Controlled Failures
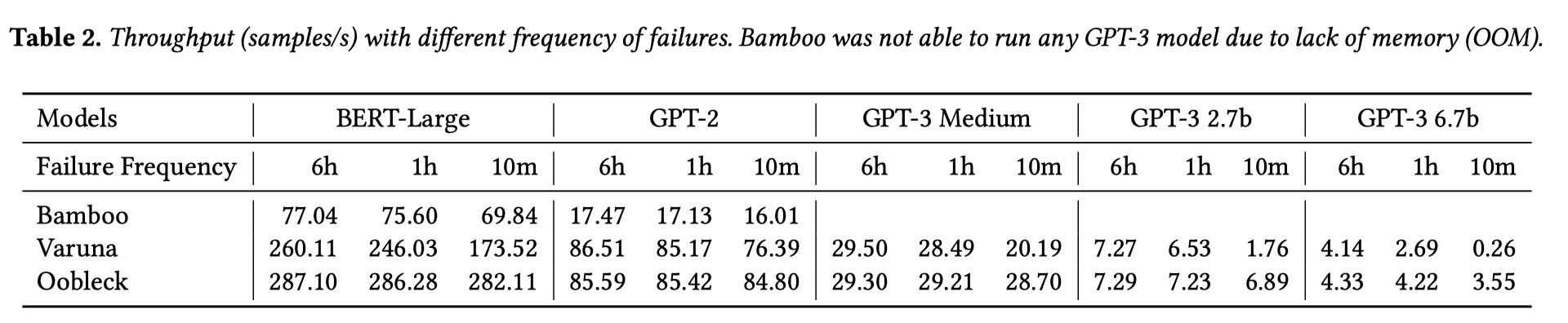
周期性控制节点故障, 不新增节点, 直到节点减半至15个. Oobleck在故障更频繁的情况下有较优的效果.
- Throughput in Spot Instance Traces
从 Bamboo 中借用了Spot Instance节点可用性变化的真实trace,并使用Bamboo的工具重放了 12 小时的trace。trace中的事件来自亚马逊EC2 P3实例(p3.2xlarge和p3.8xlarge)和GCP的a2-highgpu-1g实例。EC2 和 GCP 实例平均每 7.7 分钟和 10.3 分钟发生一次节点抢占事件。这些trace记录也包括节点增加情况, 实验通过可用性事件模拟在实际集群中进行.

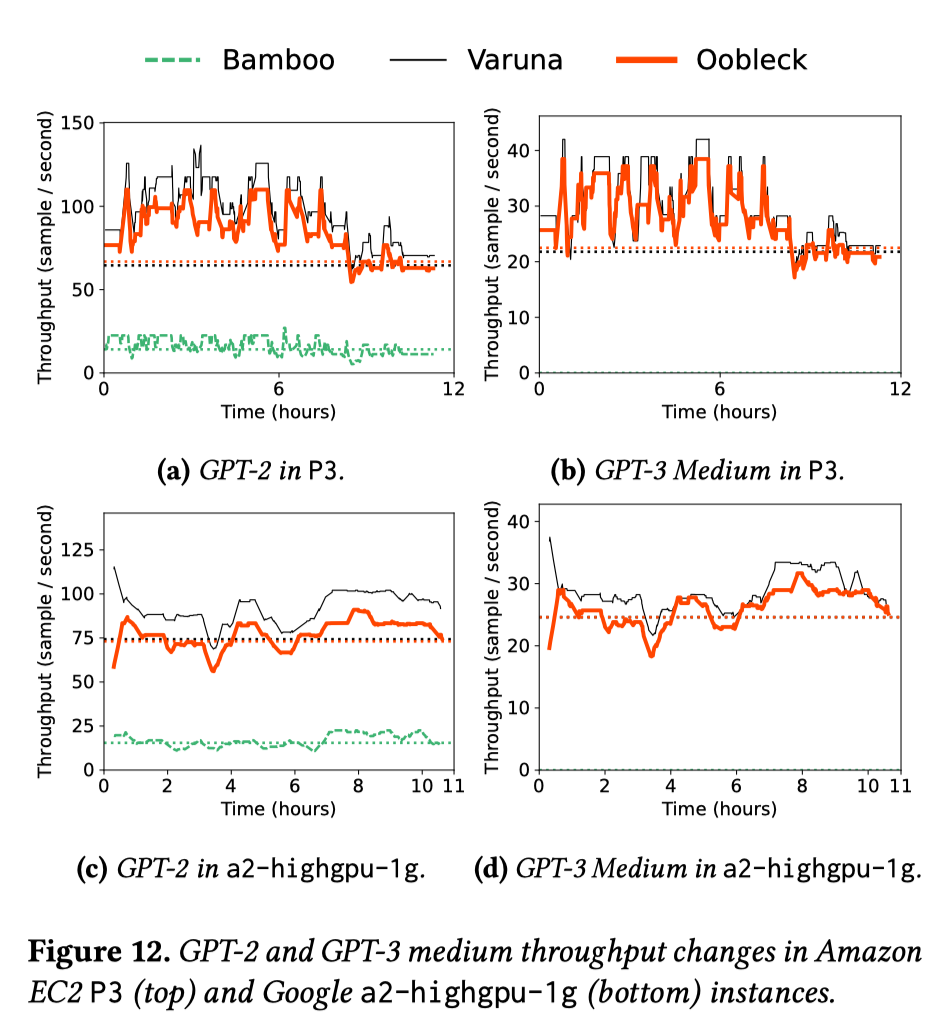
图10在正文, 图12在附录, 作者说图12的情况和图10中bert-large的情况类似…
Bert-large中Varuna和Oobleck性能相当, 模型变大后, Oobleck性能更优. GPT-3 6.7B中Varuna 一直处于挂起状态, 因为节点可用性的频繁变化会更频繁地触发 Varuna 的全面重新配置, 重新配置时间久于变化间隔.
-
Ablation Study:
- Overhead of Oobleck Planning
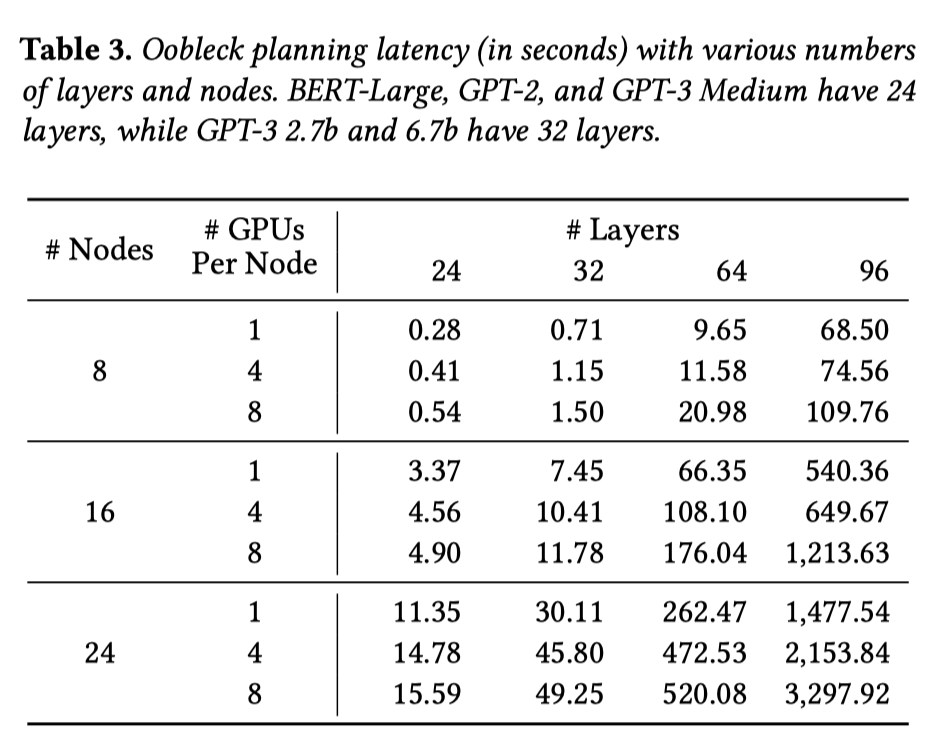
建立流水线模板的时间, 只需要进行一次.
- Throughput Breakdown
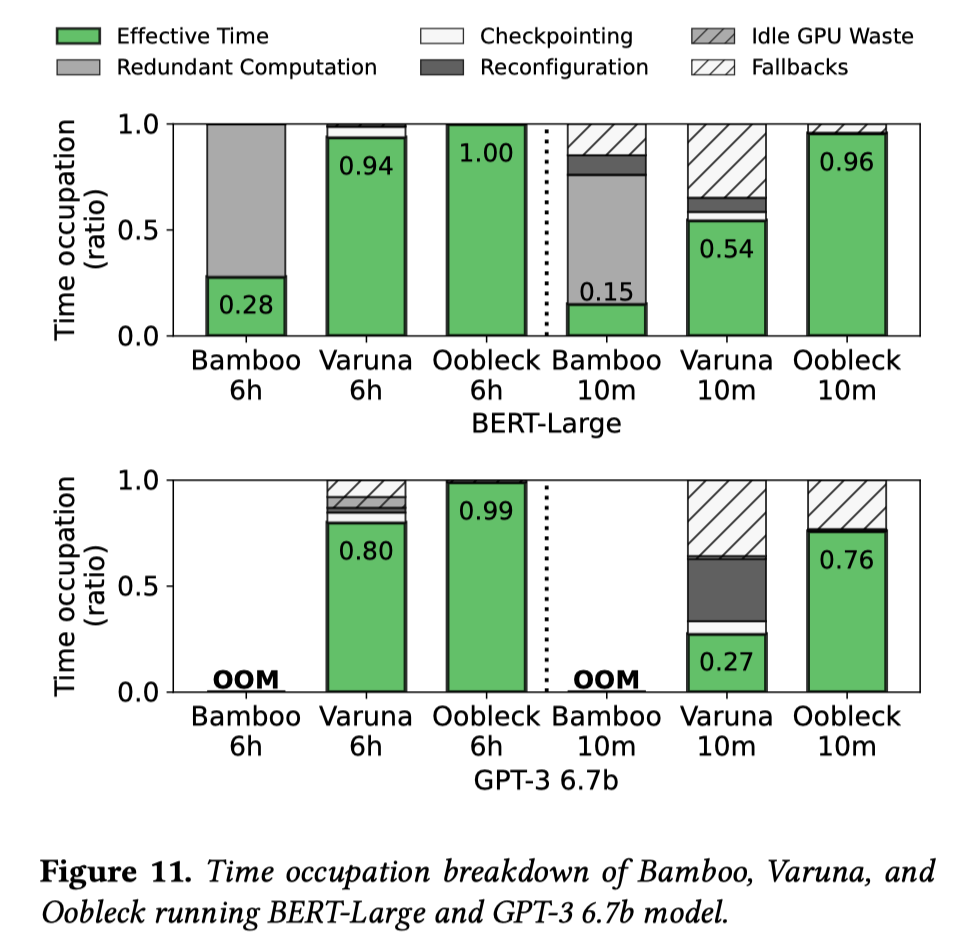
其中Fallbacks即由于迭代中间发生故障而损失一些训练进度。Varuna必须回退到上一个检查点,而Bamboo和Oobleck最多损失一次迭代。
-
Impact of Checkpointing Overhead

Varuna 的开销主要来自检查点存储和完全重启, 因此可以完全消除检查点存储的开销以进一步分析故障的影响的结果, 检查点存储从每 10 次迭代提高到每 2 次迭代. 现在Varuna的开销主要为完全重启(full restart), 包含框架初始化和加载上次检查点的开销.
总结
- 流水线模板+动态重配置的方法解决容错问题很有创新性, 整套解决方法都很直观且有效, 工作比较有启发性
- 实验结果表明在出错比较频繁的情况下比较有优势
- 目前来说容错问题感觉还没有特别通用的场景, 所以目前的工作或多或少都有比较固定的适用场景