EasyScale: Elastic Training with Consistent Accuracy and Improved Utilization on GPUs
作者: Mingzhen Li, Wencong Xiao, Biao Sun, Hanyu Zhao, Hailong Yang, Shiru Ren, Zhongzhi Luan, Xianyan Jia, Yi Liu, Yong Li, Wei Lin, Depei Qian
机构: Beihang University, Unaffiliated
备注: SC23
链接: https://dl.acm.org/doi/10.1145/3581784.3607054
Motivation
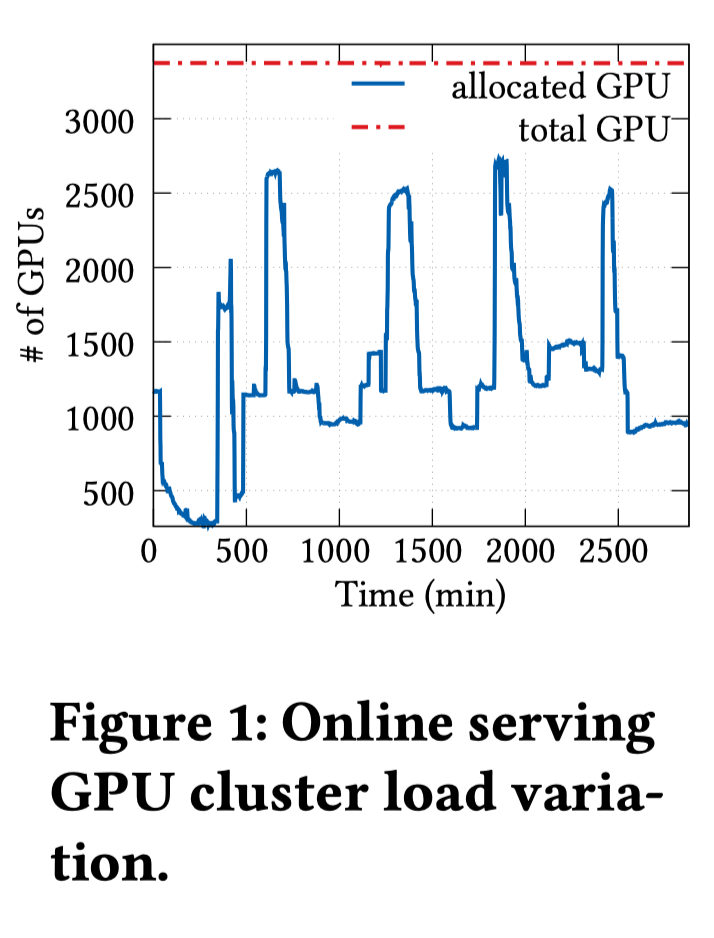
应用弹性训练的需求
-
大规模训练任务会有更长的分配资源等待时间(gang scheduling, 满足需求资源才会启动任务)
-
可以有更多机会利用集群的空闲资源,持续两天的GPU分配情况如下图所示:
弹性训练的不确定性
当前的弹性训练框架在工业界极少使用:
- 模型精度的不连续
由于资源的不一致,使用弹性训练框架训练模型的多次运行无法产生一致的模型精度。使用固定的不同数量的GPU 在 CIFAR10 数据集上训练 ResNet18 模型的验证精度如下图所示:

除了使用不同分配的 GPU 外,所有超参数和随机种子都为默认值,TorchElastic(TE)使用线性缩放来调整学习率,Pollux会自动调整学习率和batch size。Pollux的精度差异稍小,但是还是有一定的差异。
将训练拓展至100个epoch时,CIFAR10 上各个类的准确度如下图所示:

其中\(\Delta\)行是精度差距。在工业场景例如对生命至关重要的自动驾驶汽车行人检测和对利润至关重要的推荐/广告系统中,各个类准确率的差异可能会使得模型不可用。此外,模型准确性的方差/不一致性的上限仍是未知数,这进一步使得从业人员在采用弹性训练时犹豫不决。
- 难以评估超参数的影响
研究人员会通过调整超参数寻求更加性能的模型,调整学习率(gamma)的训练效果如下图所示:
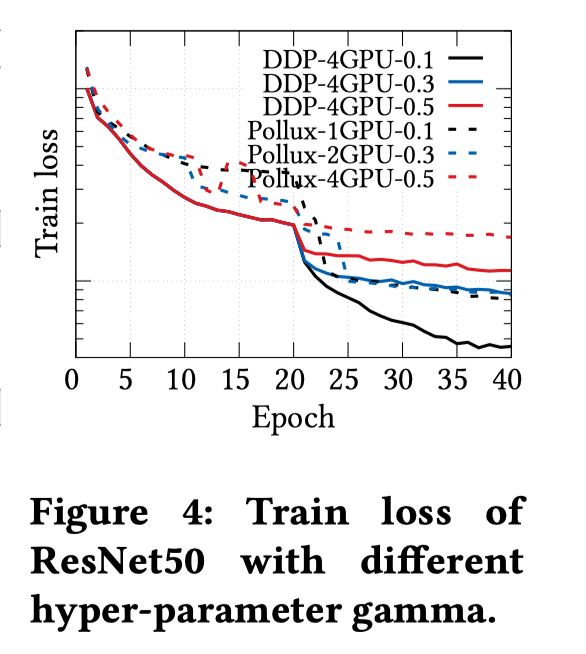
使用DDP以及固定的4GPU时,可以清楚地识别超参数 gamma 在训练过程中对训练损失的影响趋势。然而,当使用不同数量的 GPU 进行训练时,Pollux 的损失曲线会出现许多意想不到的振荡,因此对于 DL 开发人员来说并没有显示出明确的趋势,这使得现有的超参数调整知识失效,从而阻碍了模型设计阶段的工作效率。
motivation总结:
作者认为弹性训练的非确定性会导致模型精度不一致,并使超参数调整复杂化,根本原因在于现有的弹性训练框架缺乏将资源分配与模型训练过程解耦的能力,因此无法在资源弹性期间提供一致的模型精度。为了有效利用共享GPU集群上的弹性资源而不影响模型的准确性,作者认为应该提出一种新的弹性训练框架,以解决整个分布式训练软件栈的非确定性问题,从而实现一致的模型准确性。新的弹性训练框架还应提供更多机会,以提高单个分布式训练作业的吞吐量以及整个 GPU 集群的利用率。
Design
Overview
文本的目标是保证弹性训练产生和在固定GPU上数据并行训练完全一致的结果。以从4个GPU缩减至2个GPU为例,下图中(a)->(b)是一种可行的方法,即原来的4个worker在2个GPU上并行执行。但是该方法有以下几个问题:1) 多个worker在单个GPU上并行容易遇到OOM的问题或者显著的内存交换开销(非offload);2)多任务的CUDA上下文(包括训练框架和CUDA自身)内存开销不可忽视,例如,在V100 GPU 上运行 16 个worker,CUDA 上下文需要消耗 12GB GPU 内存(每个上下文约 750MB)。
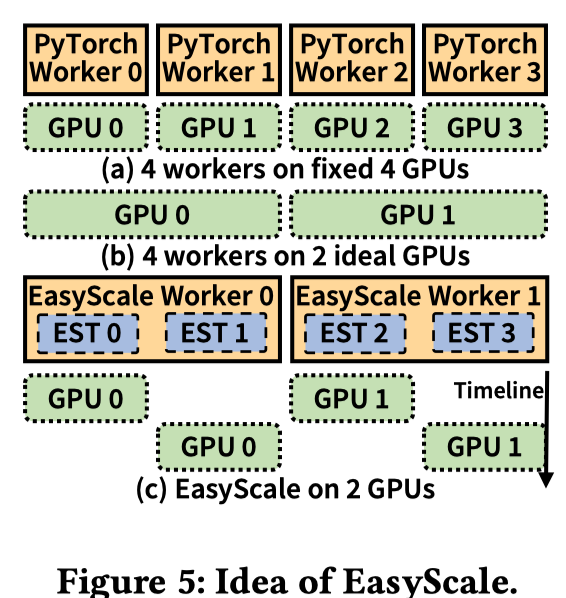
因此,实现精度一致的弹性训练的关键挑战在于训练行为(如工作者数量)的保持以及高效的GPU 资源共享 。
EasyScaleThread(EST)抽象
EST的灵感来源于线程概念和DL中普遍采用的 SPMD模型,它可以将训练过程与底层资源分配分离开来,并能灵活地通过上下文切换实现资源共享。如上图(c)所示,每个 EasyScale Worker 都在一个 GPU 上启动。原始 DDP 训练Worker (如 PyTorch Worker)的执行被视为 EST 的执行,任何 EST(即线程)都可以在训练期间动态分配给 EasyScale Worker(即进程)。
在 EasyScale Worker 中,多个 EST 以时间切分的方式轮流占用 GPU 进行训练(例如,模型正向和反向计算)。EST的训练步骤和DDP一致,EasyScale 通过用户标注的方法,给模型训练的关键步骤,如数据加载、模型反向和模型更新挂上hook,因此 EST 可以在mini-batch边界执行高效的上下文切换。在EST抽象下,用户只需考虑逻辑训练woker的数量来调整超参数(如batch size和学习率),这就与用户在固定数量的GPU上使用DDP的经验相同,并且可以通过弹性训练利用空闲资源。
使用四个 EST 进行训练时,可用资源从两个 GPU 缩至一个 GPU 的情况如下图所示:

每个EasyScale Worker维护一个共享的CUDA上下文,以避免多份CUDA上下文的额外开销(overview中的问题2)。在运行期间,每个 EasyScale Worker 一次调度一个 EST,并占用一个 GPU 在 EasyScale Worker 中执行该EST(即本地步骤)。并且在所有EST完成后进行梯度同步并更新(类似DDP)。
- 上下文切换 (TL;DR: 上下文切换在mini-batch计算间进行,只需要存梯度和RNG)
EST的上下文切换通过保存和读取在CPU上的EST traning states完成,以避免overview中的OOM问题。实现轻量级上下文切换的关键在于减少需要保存的状态。EasyScale 利用 DL 作业的特性,允许在不同 EST 之间共享和重用大多数状态。并且,EasyScale 还选择在每个mini-batch的边界(即完成前后向计算后)执行 EST 的上下文切换,从而进一步减少 GPU-CPU 的数据流量。
具体而言,减少tranining states存储大小的方法为:1)定位影响模型精度的不确定性来源并仅记录必要的状态(例如RNG的状态),2) 利用 DDP 训练的数据并行来最小化working set交换数据量。EST 的working set包括临时张量和激活、模型参数、优化状态以及梯度三类。简单而言, 就是在mini-batch反向计算后,working set只需要存储梯度。并且将梯度的存储和当前EST反向及下一个EST前向重叠。
- 适应弹性资源
EasyScale 采用On-demand Checkpoint来保留必要的状态,如上图所示,包括EST的上下文、额外状态(后文中用于实现精度一致性的状态)、 和模型及优化器参数。在重新配置的资源上继续进行模型训练时,EasyScale 会管理每个 EasyScale Worker 加载额外状态和模型,以及重新分配的 EST 的相应上下文(应该只有training states 中的第一项),以便所有 EST 都能从上次保存的状态恢复。
- 数据预处理优化(TL;DR: 重写了个可以共用的dataloader)
数据预处理通常使用CPU上的独立数据worker完成,和训练worker同时运行,用户通常会为每个训练worker设置数据worker的数量,以确保 GPU 训练不会因数据供应而受阻。如果简单地根据EST的数量来调整数据worker的数量,很容易导致大量的CPU进程,从而使训练系统不堪重负。例如,如果用户为每个训练worker配置 8 个数据worker,在 16 个EST 共享一个 GPU 的情况下,一台机器上的数据worker总数可达 128 个。EasyScale通过在所有 EST 之间共享数据worker来避免此问题,因为在任何时候一个 EasyScale Worker 中只有一个 EST 在执行,数据消耗速率与执行一个训练worker类似。
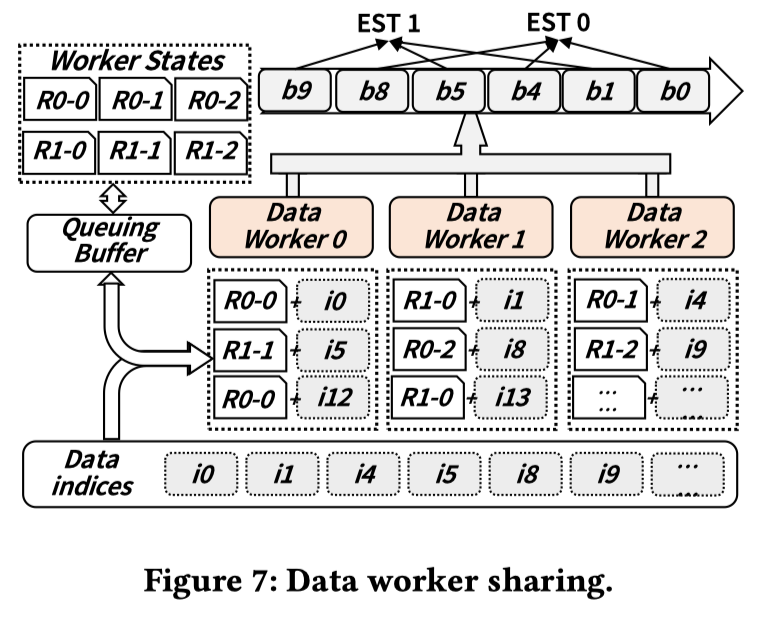
EasyScale 实现了一个共享sampler,该sampler联合考虑了 EST 的全局索引和时间切分的EST调度方式,在队列中生成数据索引。上图显示了单个 EasyScale Worker 中两个 EST 共享三个数据Worker的情况,此时 EST 的全局总数为四个(即图 6 所示的使用两个 GPU 进行训练情况)。由于数据工作者的异步执行,数据工作者的进度(如迷你批次索引)通常领先于训练进度。为了保持弹性训练状态的一致性,需要引入一个队列缓冲区,用于记录EST 未消耗的mini-batch时数据Worker states(如 RNG 的状态),数据Worker j 处理 EST i 的数据时的Worker states表示为 Ri-j,为平衡负载,EasyScale 中的数据Worker轮流从队列缓冲区获取给定数据索引的Worker states(如 Ri-j)进行数据预处理,数据预处理完成后将其提交回队列缓冲区。在On-demand Checkpoint过程中,这些数据Worker states被归类为额外状态。
非确定性消除
为了解决训练过程中的非确定性问题,本文采用了一种自上而下的方法来比较 EasyScale 和 DDP 的张量。本文使用相同数量的worker和不同的配置进行实验,以确定bitwise级训练准确性的影响因素,找到了以下三类不确定因素的来源:
- implicit framework state
框架维护的隐式states,包括RNG状态,BatchNorm的前向更新参数等。
- communication mechanism
弹性资源会带来不同的梯度桶建立方法,带来不一样的AllReduce通信结果。
- operator implementation
算子实现会有精度差别。框架、编译器、或者cuDNN会根据profile结果自动优化算子kernel的实现方法;部分内核的实现方法和SM数量及低位组件有关,对GPU类型有要求。
非确定性的解决方法
EasyScale为弹性训练定义了不同级别的确定性:
- D0: Static determinism
框架层面的确定性,包括固定RNG,在 on-demand checkpoint 里的extra state记录数据Worker RNG,在EST上下文中也记录RNG(理解应该还是training states 中的第一项)。并且在框架层禁用了基于profile的算子选择,并选择确定性内核实现(例如,不含atomic instructions)。
- D1: Elastic determinism
D1中解决通信机制中 D0 未解决的非确定性问题。每个 EST 分配一个恒定的虚拟通信rank,并在checkpoint中存储梯度桶的索引。当训练资源伸缩时,训练将使用checkpoint重新开始,使用存下的梯度桶索引。并且禁用通信重建。
- D2: Heterogeneous determinism
为了使不同的GPU获得相同的计算结果,Easyscale开发了与硬件无关的算子实现,主要涉及两个方面: 1) 修改对SM数量和线程数量有要求的算子(例如 PyTorch 中的 reduce、dropout),将数量要求改成可在任何类型 GPU 上运行的数量; 2) 在库调用中固定算法标识符(algo_id)来选择相同的算子实现(例如 cuDNN 中的卷积,以及 cuBLAS 中的 gemm、gemv)。
D0和D1开销较低,因此默认开启,D2因为放弃使用优化的kernel则会有明显开销。因此EasyScale会分析模型以确定是否依赖于特定于硬件的内核优化,如果没有,则启用 D2并且弹性训练时可以使用异构 GPU,反之EasyScale 将限制其使用同构 GPU。
EasyScale 不会重写运算符,只会选择确定性的运算符实现,或为现有运算符指定允许的 SM/线程数量。目前已经支持下表所示的多种流行模型。

EasyScale Scheduler
本文设计了EasyScale Scheduler以提高训练任务吞吐量和集群利用率, EasyScale Scheduler分为两层,如下图所示,inter-job调度器负责集群的任务资源分配;intra-job调度器负责协调 EST 和当前分配的 GPU。
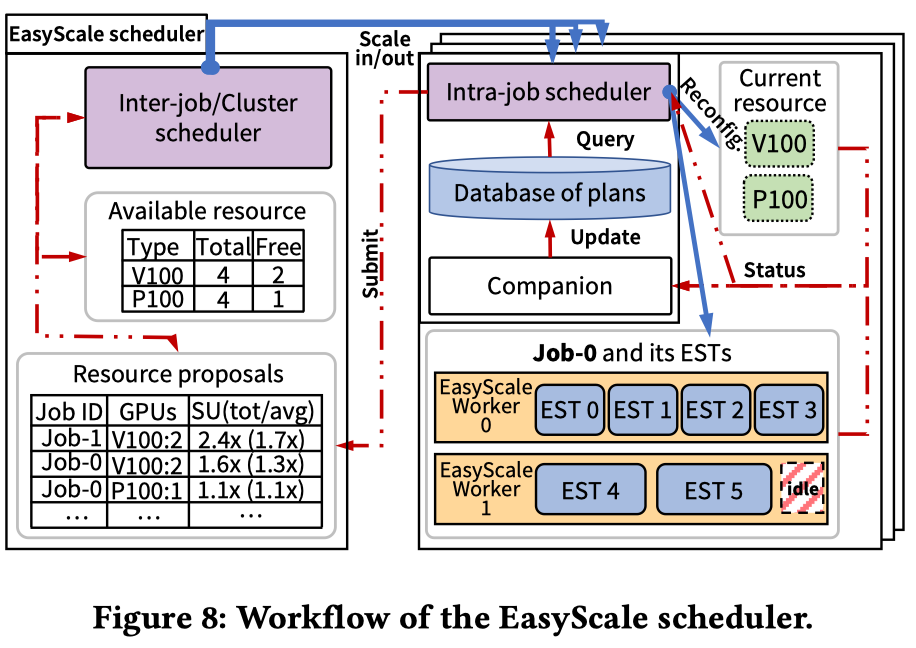
每个intra-job调度器利用一个companion module 来维护 database of plans。intra-job调度器会尝试使用增加同构 GPU进行扩展,并且根据吞吐量预估的增长情况选择top-K个候选plan作为resource proposals提交给inter-job调度器,inter-job调度器则根据集群情况,批准intra-job调度器的调度plan。
- Intra-job调度器
使用database of plans和companion module生成EST 到 GPU 的映射,根据以下规则1)在当前可用的 GPU 资源下,查询database of plans并应用估计吞吐量最高的 Top-1 配置;2)假设允许任务增加训练资源,它会查询database以探索新的配置,计算增加的 GPU 数量和预估加速比,然后形成resource proposals,并根据批准的proposal 进行配置。此外,如果观察到使用额外资源时速度变慢,会退回到使用以前的资源,并释放新分配的资源。
- Companion module
companion module根据GPU类型和EST最大数量来维护 database of plans,各plan包括 GPU 数量、EST 到 GPU 映射、基于任务信息和cost model的预估吞吐量。
Cost model: GPU 的可用数量 \(N_i\) ,其中 i 代表 GPU 类型;与workload相关的计算能力\(C_i\), 单位是mini-batch/s;给GPU类型i可以分配的EST最大数量为\(A_i\)。 此外,过载因子 ( \(f_{overload}\)) 表示当前请求的 GPU 类型中的最高过载,因为单种 GPU 类型承担过多的 EST时,会由于 Sync-SGD 减慢其他 GPU 的速度。并且引入了waste指标代表由于负载不平衡而浪费的计算能力的数量,包括1)分配的EST不能完全利用GPU算力(公式1b,1c);2) EST 总数 ≥ EST最大数量 \(maxP\)(公式 1a)。

- Inter-job调度器
Inter-job调度器维持一个可用资源表,适应弹性的集群资源;并且使用贪心算法评估提交的proposal,即倾向于接受具有单位更高加速比的proposal,如果多个proposal提供相同的加速,优先考虑 GPU 更多的proposal。
实现
EasyScale任务在Docker中运行,Scheduler和on-demand checkpoint在 Kubernetes 上实现,并且重写了个ElasticDDP的分布式数据并行通信库实现EST。
实验
小规模实验
实验环境:4x8 V100 server, 8x2 P100, 4x4 T4。
精度一致性
训练划分成3个stage:stage 0为4xV100; stage 1为2xV100 ; stage 2为1xV100+2xP100。 从stage 0到stage 1的变化资源弹性,从stage 1到stage 2的代表资源异质性。每个stage 训 100 个mini-batch。Baseline为4 个 V100的 PyTorch DDP,DDP-homo 使用固定随机种子和确定性算法以确保再现性,DDP-heter 开启异构kernel选择。
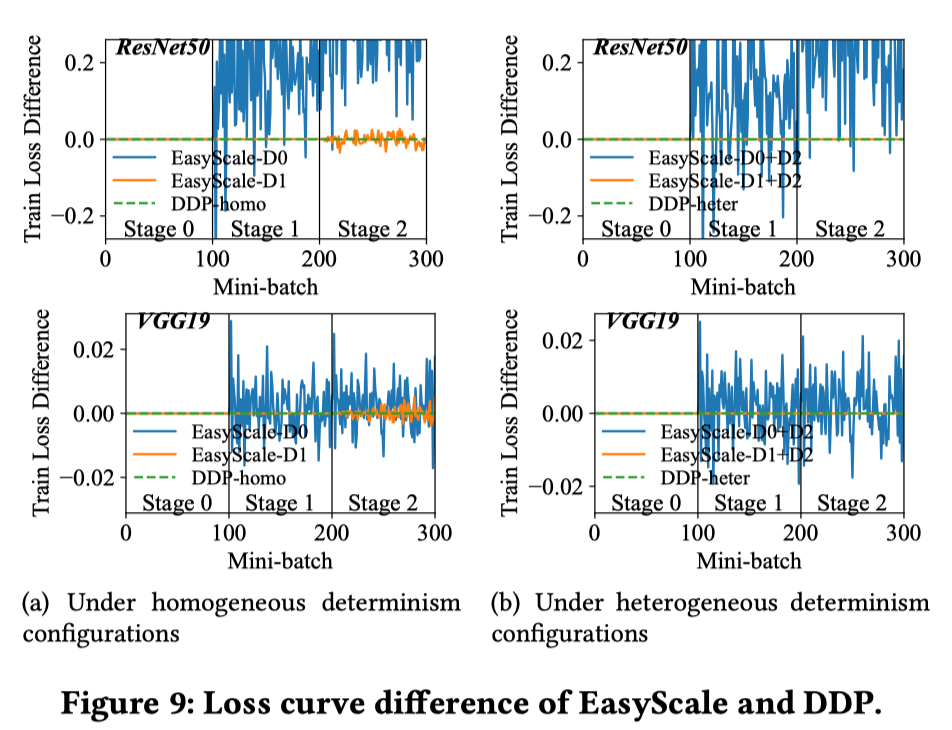
通过比较D0与D1,以及D0+D2与D1+D2,可以说明D1对弹性训练的重要性。通过比较D1和D1+D2,可以说明异构的影响。
GPU resource sharing
baseline:worker packing(OSDI 18), 一个在多个 Worker 之间复用同一 GPU的方法,是实现准确性一致性和资源弹性的另一种潜在方法。
下图展示了吞吐量和内存使用情况,虽然worker packing由于多个内核并发执行使 GPU 利用率更高, GPU 内存使用量逐渐增加,EasyScale 的 GPU 内存使用量保持不变。

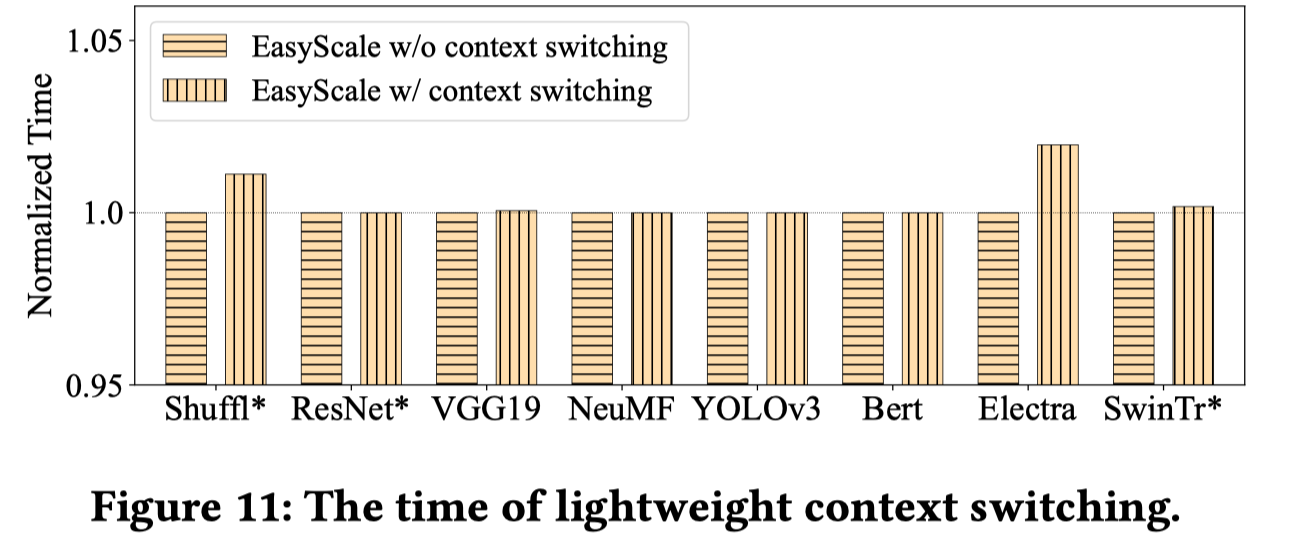
下图展示了EST上下文切换的额外开销,关闭上下文切换时无法保证精度一致,实验说明大多数情况EST上下文切换的开销很低:
保持精度的开销
在V100、P100和T4 GPU(从左到右)上的实验表示了EasyScale的额外开销,主要影响为是否能开启优化过的kernel:
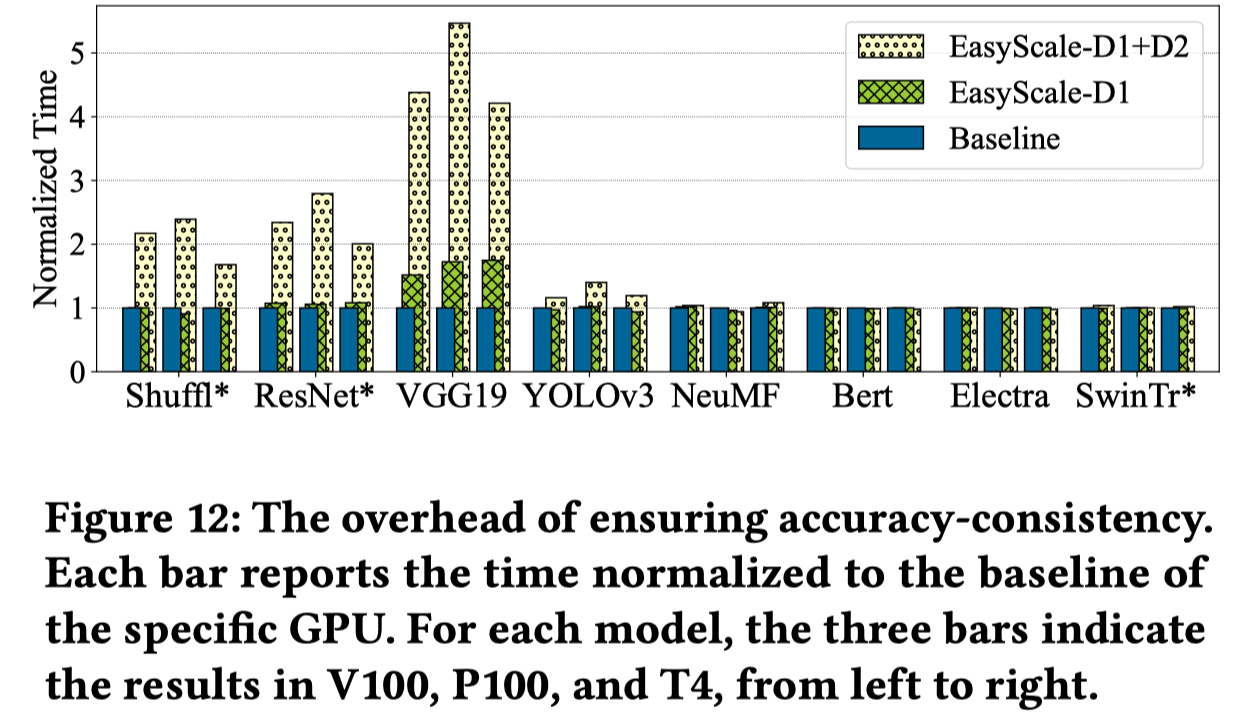
EST抽象引入的梯度复制(EST0-6)及同步(EST7)开销,因为EST0-6的梯度复制overlap在前反向计算中,会有更小的开销。

Trace experiment
实验环境:32 V100 GPUs, 16 P100 GPUs, 16 T4 GPUs.
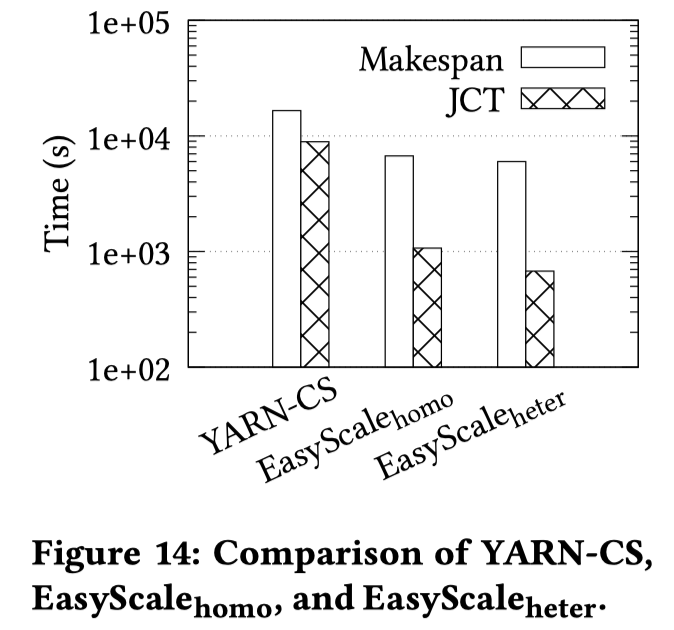
使用worker packing(OSDI 18)trace的任务到达时间进行实验。baseline为YARN-CS(ATC 19),使用FIFO 模式来处理作业。 EasyScale 有两种配置:1)EasyScale homo,作业只能使用同构 GPU; 2) EasyScale heter ,其中作业可以使用异构 GPU。
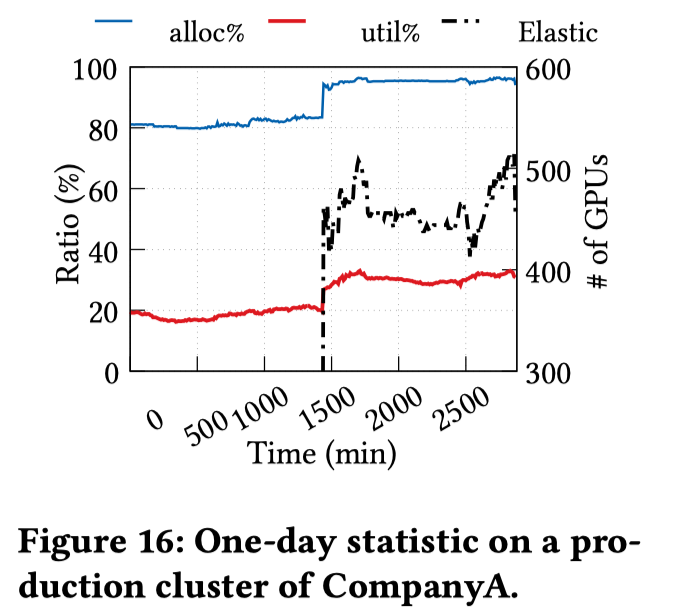
Cluster experiment
在3000多个GPU的共享集群中进行了实验,实验任务主要为推理任务或GPU开发(例如 Jupyter Notebook)。GPU推理任务视为有保证配额的生产任务,并将 EasyScale 任务视为非生产任务以利用 空闲 GPU。 下图中的虚线为easyscale的上线时间点,在一天的统计中,弹性EasyScale作业平均使用459个临时空闲的GPU。