QLORA: Efficient Finetuning of Quantized LLMs

一种高效LLMs微调方法,48G内存可调65B 模型,调优模型Guanaco 堪比Chatgpt的99.3%!
本文是华盛顿大学刚刚发布的一篇文章。作者提出了QLoRA,它是一种「高效的微调方法」,可以在保持完整的16位微调任务性能的情况下,将内存使用降低到足以「在单个48GB GPU上微调650亿参数模型」。QLORA通过冻结的4位量化预训练语言模型向低秩适配器(LoRA)反向传播梯度。作者公布了他们训练的系列模型Guanaco,与之前公开发布的所有模型相比,在Vicuna基准测试中表现更好,「只需要在单个GPU上微调24小时就能达到ChatGPT性能水平的99.3%」 。
1 Introduciton
大型语言模型(LLM)调优是提高其性能的最有效的方式,它允许我们添加所需的内容或删除不需要的内容。但是,「微调非常大的模型的成本过高;对650亿参数的LLaMA模型进行进行16位微调需要超过780GB的GPU内存」。虽然最近的量化方法可以减少LLM的内存占用量,但是这些技术仅适用于推理,并不适合在训练过程中使用。
本文首次证明可以在不降低任何性能的情况下微调量化4-bit模型。提出了一种高效的模型训练方法QLoRA,该方法使用一种新颖的高精度技术将预训练模型量化为4-bit,然后添加一小组可学习的低秩适配器权重( Low-rank Adapter weights),这些权重通过量化权重的反向传播梯度进行调优。——一会儿详细讲
与16-bit完全微调基线相比,QLORA 将微调65B参数模型的平均内存需求从 >780GB降低到 <48GB,并且不会降低模型预测性能。「这标志着LLM调优发生了重大转变,大模型的调优并非遥不可及」:现在是迄今为止最大的公开可用模型,可在单个 GPU 上进行微调。作者使用 QLORA,训练了 Guanaco 系列模型,在单个消费类 GPU 上训练不到12小时,模型在 Vicuna 基准测试中达到了 ChatGPT 性能水平的97.8%;在单个专业级GPU上训练了不到24小时,模型在 Vicuna 基准测试上达到了 ChatGPT 性能水平的99.3%;在部署过程中,最小的 Guanaco 模型(7B 参数)仅需要 5 GB 的内存,并且在 Vicuna 基准测试中比 26 GB 的 Alpaca模型高出20个百分点以上。
2 背景知识
2.1 预训练–finetune
预训练:大数据集,计算开销大,硬件要求高,只需要训一次
finetune:特定任务数据集,计算开销没那么大,硬件要求没那么高,根据下游任务训练
- 存在的问题:
1、所有参数都参与更新,内存占用大,太过低效
2、不同任务训练出的模型不同,不方便迁移
2.2 PEFT (Parameter-Efficient Fine-Tuning)
- 最小化微调参数的数量和计算复杂度
- 更容易finetune
- 更方便迁移
Adapter:设计了如下图所示的Adapter结构,将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。

- 存在的问题:
改变了Transformer结构,加入了额外的层,增加了Inference的时间
2.3 LoRa(Low-Rank Adaptation of LLMs)
有研究者对语言模型的参数进行研究发现:语言模型虽然参数众多,但是起到关键作用的还是其中低秩的本质维度(low instrisic dimension)。
受到该观点的启发,提出了Low-Rank Adaption(LoRA),设计了如下所示的结构,在涉及到矩阵相乘的模块,引入A、B这样两个低秩矩阵模块去模拟Full-finetune的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。


冻结一部分,训练一小部分
- 这样做的好处:
1、相比于原始的Adapter方法“额外”增加网络深度,必然会带来推理过程额外的延迟,该方法可以在推理阶段直接用训练好的A、B矩阵参数与原预训练模型的参数相加去替换原有预训练模型的参数,这样的话推理过程就相当于和Full-finetune一样,没有额外的计算量,从而不会带来性能的损失。
2、方便迁移。不同的下游任务训练出不同的A和B,如果切换任务,就更换成不同任务的A和B就可以实现。
2.4 LLM的量化

3 QLORA Finetuning
提出了三种方法:
- 4-bit NormalFloat Quantization
- Double Quantization
- Paged Optimizers
3.1 QLORA总体设计

在LoRa基础上,将预训练部分使用4-bit量化存储,上图蓝色部分量化成4-bit
计算中中间参数,以及右边Adapter使用BF16
计算之前,要把4-bit的参数转化成BF16
计算过程如下:

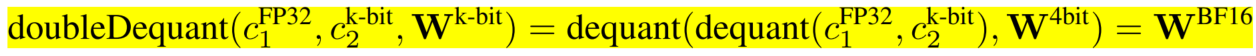
3.2 4-bit NF Quantization
Quantile quantization(分位数量化)
预训练的权重通常具有零中心的正态分布,标准差为σ。通过缩放σ,可以使得分布恰好适应NF的范围。
对于NF,设置了一个任意的范围[-1, 1]。因此,数据类型和神经网络权重的分位数都需要被归一化到这个范围。
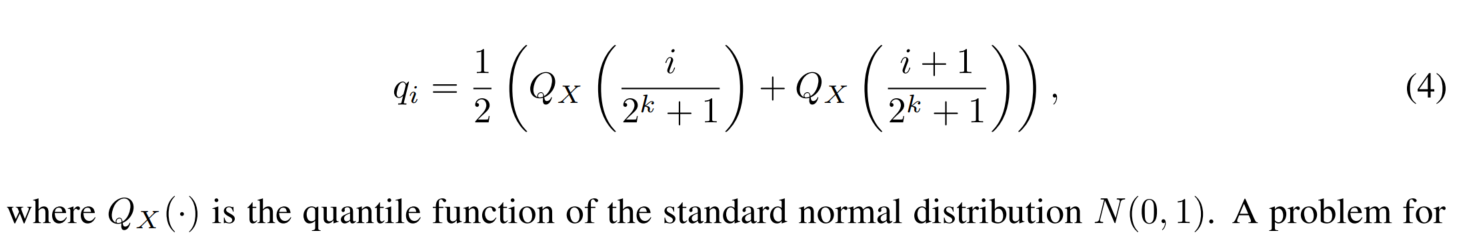
3.3 Double Quantization
对量化常量进行了量化,以达到进一步内存节约。
举个例子,64个w / block,总共有256个block。
每个block需要一个FP32来存scale常量,总共额外需要256个FP32,这样平均每个数就多了32/64=0.5bit
双量化让这个scale常量也量化,用FP8表示,然后用一个FP32的scale常量2,此时,总共额外需要256个8+一个32,平均每个数(256x8+32)/ (256x64)=0.127
3.4 Paged Optimizers
NVIDIA的统一内存特性可以在GPU RAM偶尔不足的情况下,实现CPU和GPU之间的数据传输,以确保GPU处理过程无误。这个特性类似于CPU RAM和磁盘之间的常规内存分页。作者利用这个特性,当GPU RAM不足时,把数据转移到CPU RAM,并在优化器更新步骤中需要的时候重新拿回GPU中。
4 QLoRA vs. Standard Finetuning
The main question now is whether QLoRA can perform as well as full-model finetuning.
Furthermore, we want to analyze the components of QLoRA including the impact of NormalFloat4 over standard Float4.
1、验证QLORA的表现,以及分析r和适用范围

we find that the most critical LoRA hyperparameter is how many LoRA adapters are used in total and that LoRA on all linear transformer block layers are required to match full finetuning performance.

2、验证4NF+DQ的作用
使用0-shot accuracy



Summary: Our results consistently show that 4-bit QLORA with NF4 data type matches 16-bit full finetuning and 16-bit LoRA finetuning performance on academic benchmarks with wellestablished evaluation setups. We have also shown that NF4 is more effective than FP4 and that double quantization does not degrade performance. Combined, this forms compelling evidence that 4-bit QLORA tuning reliably yields results matching 16-bit methods.
第一部分告一段落,主要介绍了QLORA的总体结构和使用的技术。
将finetune看成了两个部分:
- 提前预训练好的使用低精度量化,来减小内存占用,等同于post-quantitation,让量化后与原本的更相近。
- 用一个低秩矩阵模仿原本的finetune,由于参数少,不需要用更低精度
5 Guanaco
使用QLORA训练了一个聊天机器人 Guanaco
在Vicuna基准测试中超越了所有以前公开发布的模型,达到了ChatGPT性能水平的99.3%,而只需要在单个GPU上微调24小时。
6 Limitations and Discussion
We did not establish that QLORA can match full 16-bit finetuning performance at 33B and 65B scales.
We did not evaluate on other benchmarks such as BigBench, RAFT, and HELM, and it is not ensured that our evaluations generalize to these benchmarks.
An additional limitation is that we did not evaluate different bit-precisions, such as using 3-bit base models, or different adapter methods.
7 Broader Impacts
Our method will make finetuning widespread and common in particular for the researchers that have the least resources, a big win for the accessibility of state of the art NLP technology.
QLORA can be seen as an equalizing factor that helps to close the resource gap between large corporations and small teams with consumer GPUs.
Another potential source of impact is deployment to mobile phones.